Abstract: Aiming at the problems of traditional methods in human behavior recognition, such as the lack of scalability, a serialized research idea is proposed to extract the feature vector of the skeletal map. The SVM is used to train and identify static actions, and the sequence can be expressed as a dynamic action. As long as rich static action library, you can achieve a variety of dynamic action recognition, has a very good scalability. In order to reduce the influence of static motion recognition errors, an error correction algorithm based on previous and following information is proposed. Experiments show that the algorithm has high recognition accuracy, and has good robustness and real-time performance.
0 Preface
With the development of science and technology, the computing power of computers has been greatly improved, and the processing of big data has gradually been realized. The human behavior gesture recognition developed on this basis provides a basis for human-computer interaction, video surveillance, and smart home applications. In recent years, researchers have done a lot of research on human behavior recognition and achieved many important results. However, the accuracy of identifying complex human behaviors is still low, and it still needs to be improved.
Visual-based human behavior recognition methods [2] can be divided into two categories, one based on template matching [3] and one based on machine learning [4]. The template matching method determines the current template as the most similar action process by calculating the similarity between the current action and the template in the template library. IBANEZ R and SORIA A et al. extracted body motion trajectories and used dynamic time warping (DTW) and Hidden Markov (HMM) algorithms to identify human behavior based on template matching [5]. The machine learning method trains samples by extracting sample features to obtain a classifier that has the ability to predict unknown samples. TRIGUEIROS P and RIBEIRO F et al. compare the application of several machine learning algorithms in gesture recognition [6]. However, these algorithms are all designed for a specific behavior. When extra behaviors need to be detected, they need to be redesigned and have poor scalability.
This article uses the skeletal map data collected from Kinect [7] (provided by the MSRC-12 Gesture Dataset database [8]). The bone image extracted by Kinect can overcome the interference caused by external factors such as the intensity of light, and has strong robustness. Sex; extraction of bone features, and the use of machine learning algorithms to classify static actions, and ultimately form a sequence; from the sequence to identify the sequence of actions that need to be identified to represent the dynamic action recognition process, this process has a very good real-time and Expandability.
1Feature extraction based on skeletal map
It is very valuable to select the feature extraction of human features that can fully express a certain action of the human body without too much redundant information. According to the theory of human mechanics, this paper presents the human behavior gesture by extracting four joint point vectors, five joint point angles, and four joint point distance coefficients.
1.1 Joint point vector extraction
As shown in FIG. 1, the four joint point vectors are VSL-EL, VSR-ER, VHL-KL, and VHR-KR. Take the left upper arm as an example, calculate the left upper arm vector. It is known that the left shoulder (ShoulderLeft) joint point coordinates are SL (Sx, Sy, Sz) and the left elbow (ElbowLeft) joint point coordinates is EL (Ex, Ey, Ez), then the left upper arm joint point vector calculation method is as follows (1 ) as shown. Other joint point vectors and so on.
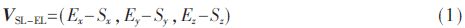
1.2 joint point angle extraction
Four joint point angles are extracted based on the original vectors. Joint joint vector can describe the activity of left arm, right arm, left leg and right leg of the human body. In FIG. 1, θEL, θER, θKL, and θKR respectively indicate the left elbow joint point angle, the right elbow joint point angle, the left knee joint point angle, and the right knee joint point angle. θHC represents the angle between the vector from the center of the buttocks to the head and the vector in the vertical direction. It can indicate the degree of bending of the human body and describe the active state of the whole body. The angle can be calculated by equation (2).

Where V1 and V2 represent two joint point vectors, respectively, and θ represents the angle between the two joint point vectors.
1.3 Joint point distance coefficient extraction
In order to make the selected features more sensitive to upper limb activities, four joint point distance coefficients were added. In Figure 1, a is the joint vector from the center of the hip to the head, b is the joint vector from the head to the right hand, c is the joint vector from the head to the left hand, d is the joint vector from the hip center to the right hand, e is the hip center to Left hand joint vector. The relative distance coefficients d1, d2 from the head to the right hand and the relative distance coefficients d3, d4 from the center of the hip to the left and right hands can be obtained by the equation (3).

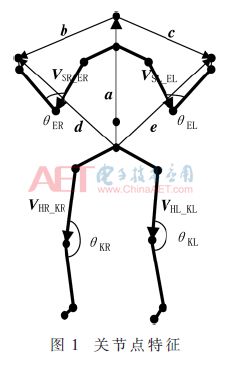
So far, the feature based on the skeletal map can be expressed as the characteristic matrix shown in Equation (4), and the total is 4×3+5+4=21 dimensions.
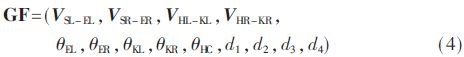
2 SVM-based recognition algorithm flow
Support Vector Machines (SVM) [9] is an algorithm used for classification. It can find the perfect hyper-plane separating things in a multidimensional space. This article uses SVM to classify actions. Take two-class support vector machine as an example. Known training sample set T:

Multiple classifiers are used to form multiple classifiers, and rich samples are used to train and identify human static gestures.
2.2 Serialization of Dynamic Actions
By setting a sampling frequency, the extracted bone maps are presented statically. Static motion recognition is performed for each frame of the skeletal map to obtain a series of long sequences. Finding the sequence to be identified in the long sequence is dynamic motion recognition. As shown in FIG. 2 , a set of actions for lifting the two hands (Start system) can be decomposed into three static actions of G1, G2, and G3. Therefore, it is only necessary to detect consecutive G1, G2, and G3 statics in the long sequence. The motion can be judged as the dynamic action of “lifting your hands and raisingâ€.
2.3 Classification error correction process
In order to reduce the impact of static gesture recognition errors on the accuracy of dynamic motion recognition, this paper proposes an attitude correction algorithm based on information before and after. Under normal circumstances, the adjacent two or more frames of data describe the same action. The algorithm flow chart is shown in Figure 3, where predict is the result of the classifier prediction and sequence is the final long sequence. First, it is judged whether the current prediction result is the same as the long sequence tail data. If the same, the current action is the same as the previous frame action, and the prediction result is added to the long sequence of the team tail; if they are not the same, it needs to verify whether the current prediction result is wrong. This algorithm determines whether the most frequently occurring data in the frame prediction result of n (15 in this paper) after the current action is equal to the current motion prediction result, and whether its proportion is greater than a certain threshold (0.5 in this paper), and if so, the current action will be The long-sequence team tail is added to the prediction result; if not, it indicates that the current motion prediction result is wrong, and the long sequence tail data remains unchanged.
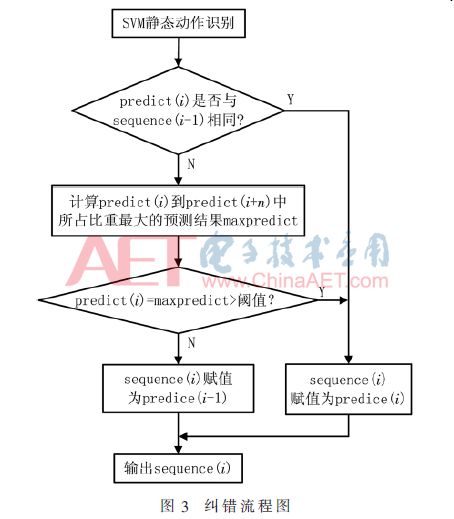
3 experimental verification
3.1 Training static actions
MSRC-12 Gesture Dataset is a Microsoft-supplied database of 12 actions. This article selects three sets of actions: Start system, Duck, and Push right, as shown in Figure 2, Figure 4, and Figure 5.
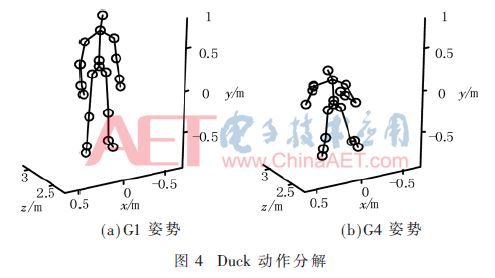
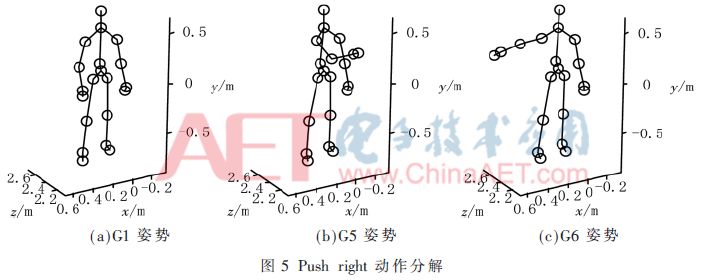
Obviously, most volunteers do not have the same time to maintain a static action. In order to rationally utilize resources and facilitate handling, postures are divided into two states:
(1) The proceeding state is the intermediate state of a group of actions, that is, the overshoot of two static attitudes, which may include a relatively large range of movement gestures during the movement, G2 in Figure 2(b) and G5 in Figure 5(b). It is an ongoing state. Because the on-state cannot play a decisive role in the decision-making result, the on-state does not require very high recognition accuracy.
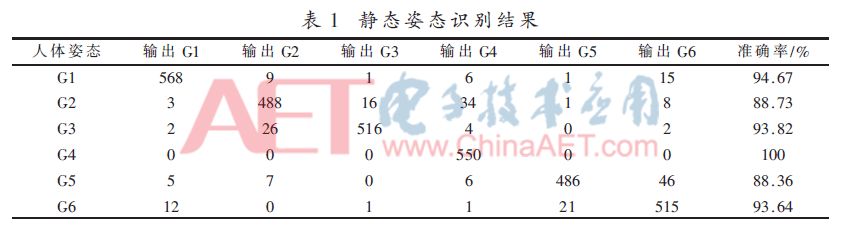
(2) The hold state is a state in which a long period of time is maintained in a group of actions and can play a decisive role in the recognition of the posture. Therefore, a high recognition accuracy rate is required. G1 in FIG. 2(a), G3 in FIG. 2(c), G4 in FIG. 4(b), and G6 in FIG. 5(c) all belong to the hold state. In the experiment, 600 frames of G1 pose were selected from 10 persons, and 550 frames of G2, G3, G4, G5, and G6 poses were selected among 5 persons. A total of 3,350 frames of data were used to train the classifier. The SVM recognition results are shown in Table 1.
3.2 Analysis of Static Operation Results
The ten-fold cross-validation method was used to test the performance of the classifier. The final average recognition accuracy was 93.12%. Table 1 shows the recognition accuracy of a single gesture. From Table 1, it can be seen that the recognition accuracy of posture recognition in the hold state is generally above 90%, achieving a high accuracy rate. The accuracy of on-the-spot posture recognition is slightly lower than that of the hold state, but from the above we can see that this has little effect on the final judgment result.
3.3 Sequence error correction
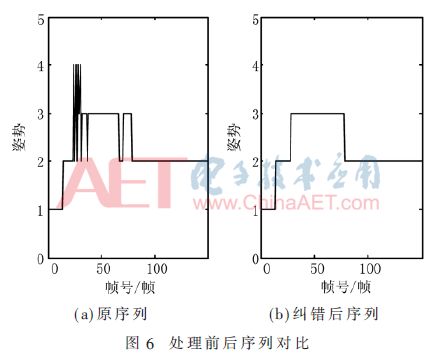
Use the method described in section 2.3 for attitude correction. Without loss of generality, for example, 150 frames of data (original sequence) were randomly selected from the experimental 3,350 frames of data, as shown in Fig. 6(a). At around the 30th frame of the original sequence, there was more misclassification of posture 2 (G2) towards the over-posture of position 3 (G3). Figure 6(b) is a sequence after error correction using the method of section 2.3. It can be seen that the entire sequence becomes much smoother, the above classification errors are suppressed, and the subsequent action recognition is greatly facilitated.
3.4 state motion recognition verification
To facilitate analysis, successive n "1"s in the error-corrected data are represented by a "1", and other postures are analogized. Take the Start system as an example. When a continuous 1,2,3 or 1,3 is detected, it can be determined that a group of Start system actions has occurred. When a continuous 1,2,3,2,1,1,2,3 is detected 1,1,3,2,1,1,3,1 determine that the Start system action is completed and return to the stance (G1). The MSRC-12 Gesture Dataset data test was used. The test results are shown in Table 2. In order to compare the advantages and disadvantages of the algorithm, Table 2 also lists the identification of the random forest algorithm in [10].

It can be clearly seen from Table 2 that compared with the algorithm of [10], the recognition accuracy of the proposed algorithm is higher. Through experiments, the specific recognition rates of the three actions of Start system, Duck, and Push right are 71.82%, 80%, and 76.36%, respectively.
4 Summary
This algorithm can realize real-time extraction of bone data, calculation of bone features, classification and recognition and formation of sequences, with good real-time. The serialized dynamic action recognition method can satisfy any combination of various actions and has a good expansion. Experiments show that this algorithm has a high recognition accuracy. However, categorizing each acquired skeletal map will undoubtedly increase the algorithm's complexity. Therefore, how to reduce the redundant classification and identification is the problem that needs to be solved in the next step of research.
OEM Laptop Ram manufacturer Memoria Ram ddr 4 4g 2666 memory sodimm 4gb ddr4 2666mhz dual channel RAM for laptop 16c PC4 21300 1Rx8
• 240-pin, unbuffered dual in-line memory module (UDIMM)
Ddr4 Desktop Memory,Ddr3 4Gb 1600Mhz,Ddr3 4Gb Ram Game Memory,Ddr3 8Gb Desktop Memory
MICROBITS TECHNOLOGY LIMITED , https://www.hkmicrobits.com