Perhaps the reader can still remember that the death of a girl with artificial intelligence not long ago. Her name is "Tay.ai" and is the result of Microsoft's artificial intelligence research. Tay has an own account on Twitter, and she can receive her instant reply just by sending her Attleet.
Tay appeared at the beginning with a fresh and lovely girlish image, but because her algorithm was set to enrich her corpora by learning netizens' dialogues, she was quickly flooded with netizens' vehemently prejudiced words that “become badâ€. A complete racist hatred of ethnic minorities, hate women, and no compassion. She became a collective of all prejudices in this society.
In the end, in order to quell public anger, Microsoft chose to kill her.
Because the purpose of machine learning is to understand people and imitate people. In the process of development, there must be a less bright side of human society. It can be said that in machine learning there are many prejudices that human society brings, but not all are as obvious as Tay.
Recently, in Google's database, it was discovered that its subtle "sex discrimination" phenomenon.
The birth of prejudiceThings have to go back two years ago, Google's several researchers launched a neural network project, the goal is to find the various combinations of words adjacent to the model, and the corpus to be used from the Google news text of 3 million words.
The resulting research results are complex, but the team found that these patterns can be displayed using vector space maps, of which there are approximately 300 dimensions.
In vector space, words with similar meanings occupy the same position, and relationships between words can be captured by simple vector algebra. For example, "men and kings are equal to women and queens" and can be represented by the symbol "man: king::woman:queen". Similar examples are, "Sister: Woman:: Brother: Man" and so on. The relationship between such words is called "word embedding."
Finally, a database containing many words embedded is called Word2vec, which is very powerful. A large number of researchers began to use it to help their work, such as machine translation and smart web search. This database was used for several years.
But one day, Boston University’s Tolga Bolukbasi and several people from Microsoft Research found that there is a big problem with this database: explicit sexual discrimination.
They issued a lot of evidence. If you ask in the database "Paris: France:: Tokyo: x", then the answer given to you by the system is x = Japan. However, if the question becomes "Father: Doctor::Mother:x", the answer given is x=nurse. Another example is the question "man: programmer:: woman: x", the answer is x = housewife.
This is very scary sex discrimination. The reason for this phenomenon is that the text in the Word2vec corpus itself is gender-biased, and the subsequent vector space map is also affected. Bolukbasi said without disappointment: "We thought that word embeddings from Google News would be less gender biased because these articles were written by professional journalists."
What is the effect?You know, Google's database has been used by researchers and developers from all walks of life, such as web search engines. In the original Word2vec, the word “programmer†has a stronger relationship with men than women, so if the employer enters “programmer resume†when searching for talent, the male resume displayed in the search results will be far behind. The front of women’s resumes is obviously extremely unfair. And all this happened unconsciously. As Bolukbasi puts it: "Word embedding not only reflects existing prejudices, but it further magnifies prejudices."
The key is: how to solve it?Bolukbasi and his colleagues gave a proposal: In theory, gender discrimination can be seen as a bending deformation of this vector space, find the source of this deformation, correct it, while maintaining the integrity of the entire system .
In practice, the most difficult part is to find out what kind of distortion the word actually refers to.
The approach they take is to find a series of words in the database that are related to the words “She: He,†which results in a huge list of gender analogies. For example: midwife: doctor, sewing: carpentry, professional nurse: physicist, prostitute: coward, hairdresser: hairdresser, nude: bare-chested, big breasts: ass, giggling: grinning, babysitter: driver and so on.
Next, the question they need to answer is whether these analogies are appropriate or inappropriate. In the face of such massive judgment tasks, the researchers have adopted "crowdsourcing" - publishing tasks on the Amazon's Mechanical Turk platform. The Amazon-Turkish robot is a crowd-sourcing platform for artificial intelligence. The research organization publishes tasks on it. The average person takes this platform and earns a certain reward. Such tasks as questionnaires are more common.
The Bolukbasi team gave each of the analogies, such as "She: He :: Midwives: Doctors," to 10 taskers to determine if the relationship was appropriate. If more than half of people believe that the relationship is biased, then the analogy relationship is deemed inappropriate and needs to be modified.
As a result, the researchers created a complete set of gender-biased word relations data. They figured out how these data affected the shape of the vector space, and how the shape of the final vector space would change by removing this deformation. They call this process "hard de-biasing."
At least not magnify these prejudicesThe end result of the improvement is satisfactory. Using the repaired vector space, the researchers produced a series of new analogies related to "She: He." The results were hens: cocks, girls: boys, daughters: sons, etc. The gender bias in this vector space has been greatly reduced.
The results of the study are shown in the figure below. The green lines show a significant reduction in the number of biased word relationships after "hard de-biased."
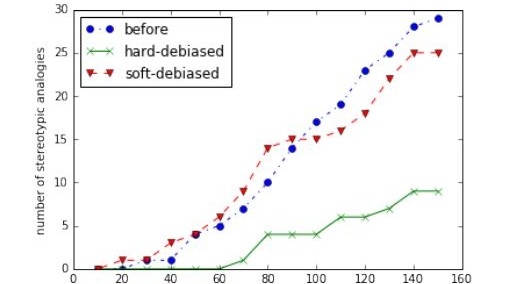
Bolukbasi said: "Through empirical evaluation, our algorithm significantly reduces gender bias, whether direct or indirect, while preserving the effectiveness of word embedding."
One view is that word embedding merely reflects prejudices already existing in society, so people should try to correct society instead of correcting word embedding. Bolukbasi and his colleagues believe that their actions are precisely in the process of correcting the entire society. "Today's computer systems are increasingly dependent on word embedding, and our little effort in word embedding ultimately hopes to improve the gender bias in society as a whole."
This is a very respectable goal. As their team concludes, "At least, machine learning should not be used to amplify these prejudices, even if it is unintentional."
Via MIT Technology Review
Aviation Plug Connector,Gx12 Butt-Joint Connector,Gx12 Aviation Cable Connector,Gx16 Wire Panel Aviation Connector
Changzhou Kingsun New Energy Technology Co., Ltd. , https://www.aioconn.com