Lei Feng Network (search "Lei Feng Net" public concern) by: The author of this article Li Ran, PhD student at the Hong Kong Polytechnic University, research direction for natural language understanding and dialogue generation.
Summary
In the past one or two years, the emerging of generative model Generative Adversarial Networks (GAN) has brought about notable progress for generative tasks. Although GAN was presented with many problems such as unstable training, later researchers improved it from the aspects of model, training technique and theory. This article aims to sort out these related work.
Although supervised learning can obtain better training results than unsupervised ones most of the time . But in the real world, there are relatively few data labels that supervise learning needs. Therefore, researchers have never given up to explore better unsupervised learning strategies and hope to learn from the massive unlabeled data about the representation and even knowledge of the real world, so as to better understand our real world.
There are many ways to evaluate unsupervised learning. The generation task is the most direct one . Only when we can generate/create our real world can we explain that we completely understand it. However, the generative models on which the generation task depends are often faced with two major difficulties .
The first is that we need a lot of prior knowledge to model the real world, including what kind of a priori, what kind of distribution, and so on. The quality of modeling directly affects the performance of our model.
Another difficulty is that the data in the real world is often very complex. The amount of calculations we will use to fit the model is often very large, even unbearable.
In the past one or two years, there was an exciting new model, which was a good escape from these two difficulties. This model is called Generative Adversarial Networks (GAN) and proposed by [1]. In the original GAN ​​paper [1], the author used game theory to interpret the ideas behind the GAN framework. Each GAN framework contains a pair of models - a generative model (G) and a discriminative model (D) . Because of the existence of D, G in GAN no longer requires prior knowledge and complex modeling of real data, but also can learn to approximate real data, and ultimately make the data it produces to be real and unrealistic - D cannot be separated. - Thus G and D reach some kind of Nash equilibrium.
The authors of [1] have given an analogy in their slides: In GAN, the generative model (G) and the discriminative model (D) are the relationship between the thief and the police. The goal of the data generated by G is to fool a police model (D). In other words, G as a thieves should try to improve his own theft method, and D as a police officer should also improve his business level as much as possible to prevent being deceived. Therefore, the learning process under the GAN framework becomes a competitive process between the generative model (G) and the discriminative model (D)—the “false sample†generated randomly from the real sample and the generated model (G). Take one and let the discriminant model (D) determine if it is true. So, in the formula, it is the form of minmax below.
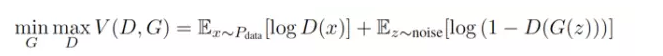
However, GAN does not need to be pre-modeled, but this advantage also brings some troubles. That is, although it uses a noise z as a priori, it is impossible to control how the generated model uses this z. In other words, the learning mode of GAN is too liberal, making the training process and training results of GAN very uncontrollable. In order to stabilize GAN, later researchers proposed many training techniques and improvement methods from the perspective of heuristic, model improvement, and theoretical analysis.
For example, in the original GAN ​​dissertation [1], each learning parameter update process is set to D update k back, and G is updated one time, which is to reduce G's "degree of freedom" consideration.

Another heavyweight work on GAN training techniques is Deep Convolutional Generative Adversarial Networks (DCGAN) [6]. [6] summarized many of the network architecture design for GAN and the training experience for such a network of CNN. For example, they replaced the pooling layer in traditional CNNs with stridified convolutional networks, thereby turning the generative model (G) in GAN into fully differentiable, resulting in a more stable and controllable training of GAN.
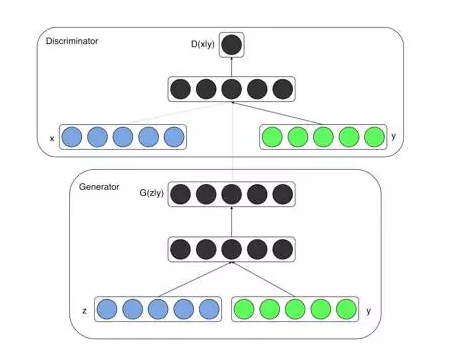
In order to improve the stability of training, another natural angle is to change the learning method . Turn pure unsupervised GAN into semi-supervised or supervised. This can add a little bit of restraint to the training of GAN, or add a little goal . The Conditional Generative Adversarial Nets (CGAN) proposed in [2] is a very direct model change. Conditional variable y is introduced in both the generative model (G) and the discriminative model (D). This y is a kind of data. Label. As a result, CGAN can be seen as an improvement of the unsupervised GAN into a supervised model. This simple and straightforward improvement proved to be very effective and widely used in subsequent related work.
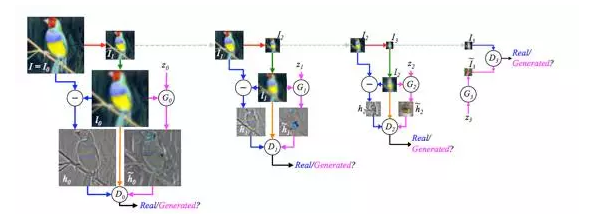
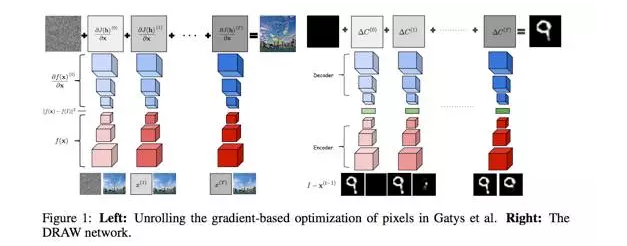
The third way to improve GAN's over-liberation is similar to the first one. Since it is too difficult to control the study of GAN, it is better to dismantle it. Instead of letting GAN learn all the data at once, let GAN complete the learning process step by step. In terms of image generation, don't let the generating model (G) in GAN directly generate an entire image each time, but let it generate part of the image. This idea can be thought of as a variant of DeepMind's well-known working DRAW. DRAW's thesis [3] started by saying that when humans draw a picture, they are rarely completed. Since we humans are not like this, why do we have to hope that machines can do it?
The LAPGAN proposed in the paper [4] is based on this idea and turns the learning process of GAN into a sequential “sequential†. Specifically, LAPGAN adopted the Laplacian Pyramid to achieve "serialization," hence the name LAPGAN. It is worth mentioning that this LAPGAN also has the idea of ​​"residual" learning (it is also related to the later ResNet). In the learning sequence, LAPGAN continuously performs downsample and upsample operations. Then in each Pyramid level, only the residuals are passed to the discriminative model (D) for judgment. Such a combination of sequential + residuals can effectively reduce the content and difficulty that GAN needs to learn, thus achieving the goal of "assisting" GAN learning.
Another work based on sequential thinking to improve GAN comes from GRAN in [5]. Unlike LAPGAN [4], where each sequential step (Pyramid level) is independently trained, GRAN combines GAN and LSTM to allow each step in the sequence to learn and generate results that make full use of the previous step. Specifically, each step of GRAN has a cell like LSTM, C_t, which determines the content and result of each step; h_{c,t} in GRAN also represents hidden states like LSTM. Since it is a combination of LSTM and GAN, then the introduction of LSTM is a matter of GAN. GRAN also models the priori generated model (G) in GAN as a hidden of prior h_z; then concatenates h_z and h_{c,t} and then passes it to C_t of each step.
The last way to improve the training stability of GAN is closer to the essence and the latest research results . This is InfoGAN [7], one of the five breakthroughs in openAI. The starting point of InfoGAN [7] is that since GAN's degrees of freedom are due to only one noise z, it is impossible to control how GAN uses this z. Then we try to find ways to make a fuss about how to use z. Thus, in [7], Z was dismantled, thinking that the “a priori†that the generating model (G) in GAN should contain is divided into two types :
(1) No more compressed z noise;
(2) Explicitly and implicitly, a set of implicit variables c_1, c_2, ..., c_L, abbreviated c. The main idea here is that when we learn to generate images, the image has many controllable and meaningful dimensions, such as the thickness of strokes, the lighting direction of the images, etc. These are c; and the rest do not know how to describe Is z.
In this way, [7] actually hopes that by dismantling a priori, GAN can learn a more disentangled representation, which can not only control the learning process of GAN, but also make the results more obvious. It is interpretable. In order to introduce this c, [7] uses the mutual information modeling method, that is, c should be generated based on the generated model (G) based on z and c, ie, G (z,c ), highly correlated—large mutual information.
Using this more detailed modelling of hidden variables, infoGAN can say that it has taken another step forward with the development of GAN. First of all, they proved that c in the infogan is really helpful to the training of the GAN, that is, it can make the generating model (G) learn the results more in line with the real data. Second, they use the natural features of c to control the dimensions of c, so that infogan can control the changes in the generated image in a particular semantic dimension.

However, in fact, infoGAN is not the first to introduce information theory into the GAN framework. This is because, before infogan, there was a work called f-GAN [8]. And, GAN itself can also be interpreted from the perspective of information theory. As mentioned in the opening chapter of this article, in the original GAN ​​dissertation [1], the author explained the GAN's thought through game theory. However, the data generated by the GAN generation model (G) and the real data can be viewed as both sides of a coin. When tossing a coin to the front, we present a real data sample to the discriminant model (D); otherwise, we show the “false†sample generated by the generated model (G).
The ideal state of GAN is that the discriminative model (D) is almost identical to the judgment of the coin, that is, the data generated by the generating model (G) is in full compliance with the real data. At this time, what GAN's training process actually does is to minimize the mutual information between the coin and the real data. The smaller the mutual information, the less information the discriminative model (D) can obtain from the observation, and the more it can only guess the result like “randomâ€. Since there is such an understanding of GAN from the perspective of mutual information, can we further transform GAN? In fact, it is possible. For example, the modeling of mutual information can be further generalized to optimization goals based on divergence. This discussion and improvement can be found in the paper [8], f-GAN.
The above improvements to the GAN are almost completed in just one and a half years, especially in the past half year. The biggest reason for this is that GAN compared the previous generative models and subtly transformed the “true and false†samples into a recessive label, thus realizing an “unsupervised†generative model training framework . This idea can also be viewed to some extent as a variant of Skip-Gram in word2vec. In the future, not only will GAN's further improvements deserve to be anticipated, but unsupervised learning and the development of generative models are also worthy of attention.
References:
1. "Generative Adversarial Nets"
2. "Conditional Generative Adversarial Nets"
3. "DRAW: A Recurrent Neural Network For Image Generation"
4. "Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks"
5. "Generating Images with Recurrent Adversarial Networks"
6. "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks"
7. "InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets"
8. "f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization"
Lei Feng Net Note: This article is authorized by the Deep Learning Lecture Center to be published by Lei Feng. If you need to reprint, please contact the original author and indicate the source of the author. You must not delete the content.
22Mm Metal Switches
22Mm Metal Switches is a larger size in the Metal Switches serious. It is designed vary from people and regions and the design of larger operation button face is for increasing the convenience and comfort when operating.
In order to create more function and save more space for this , Waterproof Metal Switch, we adopt single and dual control design, so our one switch could have multiple purposes. This Stainless Steel Switch are widely used in human interface panel, it has P67 dust-proof and waterproof function, IK10 stainless steel material damage resistance level, advanced mechanical life.

In addition, in order to meet customer requirements, our larger Anti Vandal Switches has passed the EU green environmental protection RoHS certification, the US UL testing certification, IP67 certification and TUV certification.
Moreover, customers can choose the metal button with LED light indication according to their own product requirements. The LED lamp beads are all from international brand suppliers to ensure the high life of LED lamp beads and the long-term work without discoloration effect.

22Mm Metal Switches,22Mm Waterproof Metal Switch,22Mm Stainless Steel Switch,22Mm Metal Flush Push Button Switch
YESWITCH ELECTRONICS CO., LTD. , https://www.yeswitches.com