This article contains five points of knowledge:
1. Introduction to Data Mining and Machine Learning Technology
2. Python data preprocessing combat
3. Introduction to Common Classification Algorithms
4. Classifying Iris Flower Cases
5. Classification algorithm selection ideas and techniques
I. Introduction to Data Mining and Machine Learning Technology
What is data mining? Data mining refers to a technology that processes and analyzes some existing data and finally obtains a deep relationship between data and data. For example, when placing supermarket goods, whether milk is sold with bread is higher or whether it is sold with other goods. Data mining technology can be used to solve such problems. Specifically, the problem of placing goods in supermarkets can be divided into related analysis scenarios.
In daily life, data mining technology is widely used. For example, for merchants, it is often necessary to classify their customers' levels (svip, vip, general customers, etc.). At this time, some customer data may be used as training data, and another part of customer data may be used as test data. Then the training data is input into the model for training. After the training is completed, another part of data is input for testing, and the automatic classification of the customer level is finally achieved. Other similar application examples include verification code identification, automatic fruit quality screening, and the like.
So what is machine learning technology? In a nutshell, any technology that allows the machine to learn the relationships or rules between the data through the models and algorithms we have built, and finally the technology we use is machine learning technology. In fact, machine learning technology is a cross-disciplinary, it can be roughly divided into two categories: traditional machine learning technology and deep learning technology, in which deep learning technology includes neural network related technology. In this course, the focus is on traditional machine learning techniques and various algorithms.
Because machine learning technology and data mining technology are all explorations of the laws between data, people often refer to them together. And these two kinds of technology also have very broad application scenes in real life, among them the classical several kinds of application scenes are shown as follows:

1. Classification: classification of customer ranks, verification code identification, automatic screening of fruit quality, etc.
Machine learning and data mining techniques can be used to solve classification problems, such as the classification of customer levels, verification code identification, and automatic screening of fruit quality.
Taking verification code identification as an example, it is necessary to design a scheme for identifying a verification code composed of 0 to 9 handwritten digits. One solution is to first divide some of the handwritten numbers from 0 to 9 into training sets, and then manually divide the training set, that is, map the handwritings below their corresponding numerical categories, and establish these mapping relationships. After that, the corresponding model can be established by the classification algorithm. If a new digital handwriting appears at this time, the model can predict the number represented by the handwriting, that is, which number category it belongs to. For example, if the model predicts that a handwriting belongs to the category of the number 1, the handwriting can be automatically recognized as the number 1. So the verification code identification problem is essentially a classification problem.
The problem of automatic screening of fruit quality is also a classification problem. The size, color and other characteristics of the fruit can also be mapped to the corresponding sweetness category, for example, 1 this category can represent sweet, 0 this category represents not sweet. After obtaining the data of some training sets, the model can also be established by the classification algorithm. At this time, if a new fruit appears, it can automatically judge whether it is sweet or not by its size, color, and other characteristics. In this way, automatic screening of fruit quality is achieved.
2. Regression: Forecasting, trending, etc. for continuous data
In addition to classification, data mining technology and machine learning technology have a very classic scene - regression. In the previously mentioned classification scenario, the number of categories has certain limitations. For example, the digital verification code recognition scene contains a numeric category of 0 to 9; for example, the scene of a letter verification code contains a limited category of a to z. Regardless of whether it is a numeric or alphabetic category, the number of categories is limited.
Now suppose that there is some data. After mapping it, the best result does not fall on a point of 0, 1, or 2, but it continuously falls on top of 1.2, 1.3, 1.4... The classification algorithm can not solve this kind of problem, this time can use the regression analysis algorithm to solve. In practical applications, the regression analysis algorithm can realize continuous data prediction and trend prediction.
3. Clustering: customer value forecast, commercial circle forecast, etc.
What is clustering? As mentioned above, if you want to solve the classification problem, you must have historical data (that is, correct training data created by man). If there is no historical data and it is necessary to directly classify the characteristics of an object into its corresponding categories, classification algorithms and regression algorithms cannot solve this problem. At this time, there is a solution—clustering, clustering methods directly classify the corresponding categories based on object characteristics. It does not require training, so it is an unsupervised learning method.
When can I use clustering? If there is a group of customer's characteristic data in the database, it is necessary to directly classify the customer's level (such as SVIP customer, VIP customer) according to the characteristics of these customers. At this time, the clustering model can be used to solve. In addition, clustering algorithms can also be used when predicting a business district.
4. Association analysis: Supermarket goods placement, personalized recommendation, etc.
Association analysis refers to the analysis of the correlation between items. For example, if a large amount of goods are stored in a supermarket, it is necessary to analyze the correlation between these goods, such as the strength of the relationship between bread products and milk products. At this time, an association analysis algorithm can be used to help users. The purchase records and other information directly analyze the correlation between these products. After understanding the relevance of these products, they can be applied to supermarket products. By placing highly associative products in similar locations, the supermarket sales can be effectively improved.
In addition, association analysis can also be used to personalize recommended technologies. For example, with the aid of the user's browsing history, the relevance of each web page is analyzed, and when the user browses the web page, a strongly-associated web page can be pushed to it. For example, after analyzing the browsing record data, it is found that there is a strong association relationship between the web page A and the web page C. Therefore, when a user browses the web page A, he can push the web page C to him, thus realizing the personalized recommendation.
5, natural language processing: text similarity technology, chat robots, etc.
In addition to the above application scenarios, data mining and machine learning techniques can also be used for natural language processing and speech processing, and the like. For example, calculation of text similarity and chat bots.
Second, Python data preprocessing combat
Before data mining and machine learning, the first step is to preprocess existing data. If even the initial data is not correct, then the correctness of the final result cannot be guaranteed. Only by preprocessing the data to ensure its accuracy can we ensure the correctness of the final result.
Data preprocessing refers to the preliminary processing of data and the disposal of dirty data (ie, data that affects the accuracy of results), otherwise it is very easy to affect the final result. Common data preprocessing methods are shown in the following figure:

1, missing value processing
A missing value is a feature value that is missing from a row of data in a set of data. There are two ways to solve the missing value. One is to delete the missing data and the other is to add a missing value to the correct value.
2, abnormal value processing
The reason why the outliers are generated is often that an error occurred in the data collection. For example, an error occurred when the number 68 was collected, and it was incorrectly collected as 680. Before dealing with outliers, it is of course necessary to discover these outliers first, and these outliers can often be found by drawing. After the processing of the outlier data is completed, the original data will tend to be correct to ensure the accuracy of the final result.
3, data integration
Compared to the missing value processing and outlier processing above, data integration is a simpler data preprocessing method. What is data integration? Suppose there are two sets of data A and data B with the same structure, and both sets of data have been loaded into memory. At this time, if the user wants to combine the two sets of data into a set of data, they can be directly merged using Pandas, and this The process of consolidation is actually the integration of data.
Next, take Taobao's product data as an example to introduce the actual combat of the above pretreatment.
Before data preprocessing, Taobao product data needs to be imported from the MySQL database. After opening the MySQL database, query the taob table, and get the following output:
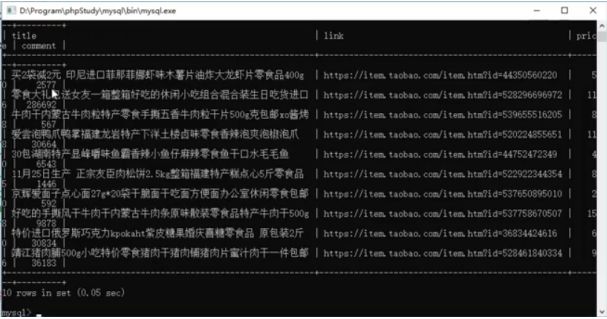
As you can see, there are four fields in the taob table. The title field is used to store the name of the Taobao product; the link field stores the link of the Taobao product; the price stores the price of the Taobao product; comment stores the number of reviews of the Taobao product (to some extent, it represents the sales of the product).
So how do you import this data? First connect to the database through pymysql (if garbled, modify the source code of pymysql), after the connection is successful, all the data in taob will be retrieved, and then the data can be imported into the memory by means of the read_sql() method in pandas.
The read_sql() method takes two parameters. The first parameter is the sql statement, and the second parameter is the connection information for the MySQL database. The specific code is as follows:

1, missing value processing combat
Dealing with missing values ​​can use data cleaning. Taking the Taobao product data above as an example, the number of reviews for a product may be 0, but its price cannot be 0. However, in fact, there are some data with price value 0 in the database. The reason why this happens is that the price attribute of some data has not been climbed.
So how can we determine that these data have missing values? The following methods can be used to determine:
First of all, calling the data.describe() method on the previous taob table results in the following result:

How to understand this statistical result? The first step is to observe the count and price fields of the comment field. If the two are not equal, there must be missing information. If the two are equal, you cannot see if there is any missing information. For example, price's count is 961600.00, while comment's count is 9650.000, indicating that at least one comment data is missing.
The meanings of the other fields are: mean represents the mean; std represents the standard deviation; min represents the minimum value; max represents the maximum value.
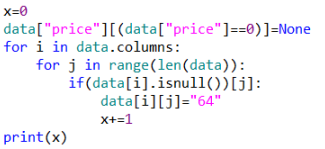
How to deal with these missing data? One way to delete this data is to insert a new value at the missing value. The value in the second method can be either an average or a median, and whether to use the average or the median depends on the actual situation. For example, the age of this data (from 1 to 100 years old), this kind of data with stable and variable grades is generally inserted into the average number, while the data with large interval of change is generally inserted into the median.
The specific operations for dealing with missing values ​​for prices are as follows:
2, abnormal value processing combat
Similar to the processing of missing values, to deal with outliers, we must first find the outliers. The discovery of outliers is often done by drawing a scatterplot, because similar data will be concentrated in a scatter plot and anomalous data will be distributed far away from this region. According to this nature, it is convenient to find outliers in the data. The specific operation is as follows:
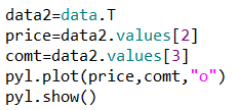
First, you need to extract price data and comment data from the data. The usual practice is to use a loop to extract, but this method is too complex, there is a simple way is to transpose this data frame, then the original column data becomes the current row of data, you can easily get the price Data and comment data. Next, the scatter plot is drawn using the plot() method. The first argument of the plot() method represents the abscissa, the second represents the ordinate, the third represents the type of the plot, and the "o" represents the scatter plot. Finally, show it through the show() method so that outliers can be visually observed. These outliers do not help in the analysis of the data. In practice, these outliers often need to be deleted or converted to normal values. The following figure is a scatter plot drawn:
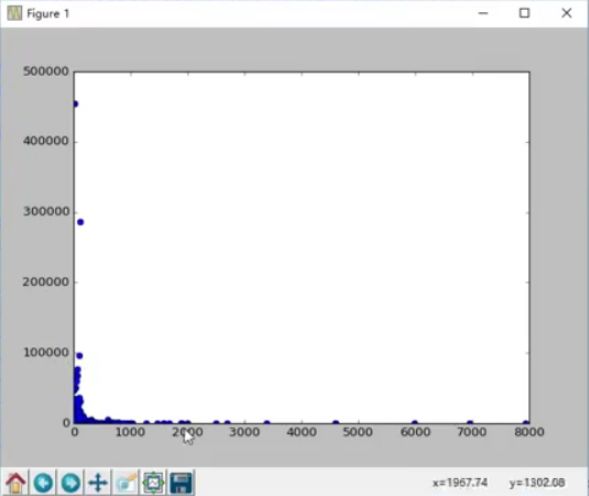
According to the above figure, if the comment is greater than 100000 and the price is greater than 1000, all the data can be processed and the effect of handling the outlier can be achieved. The implementation of the two specific processing methods is as follows:
The first is the change of value method, changing it to a median, average, or other value. The specific operation is shown in the following figure:

The second is the delete processing method, which directly deletes these abnormal data, and is also a recommended method. The specific operation is shown in the following figure:

3, distribution analysis
Distribution analysis refers to the analysis of the distribution of data, that is, whether it is a linear distribution or a normal distribution. Histograms are generally used for distribution analysis. The histogram is drawn in the following steps: Calculate Range, Calculate Group Distance, and Draw a Histogram. The specific operation is shown in the figure below:

Among them, using arrange () method to formulate the style, arrange () method first parameter represents the minimum value, the second parameter represents the maximum value, the third parameter represents the group distance, then use the hist () method to draw the histogram .
The Taobao product price histogram in the taob table, as shown in the figure below, roughly matches the normal distribution:
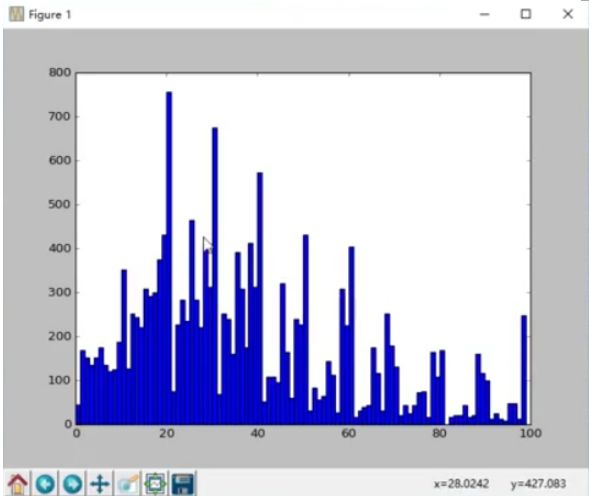
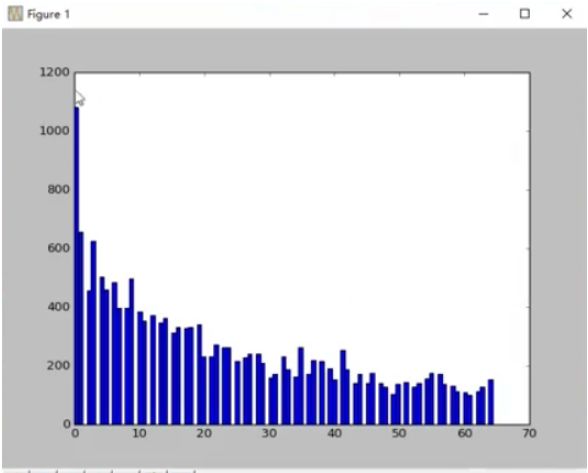
The Taobao product review histogram in the taob table is shown below and is roughly a decreasing curve:
4, the word cloud drawing
Sometimes it is often necessary to draw word cloud maps based on a piece of textual information. The specific operations for drawing are as follows:

The general process of implementation is: first use cut() to cut the word of the document, after the word is completed, organize the words into a fixed format, and then read the corresponding image according to the presentation form of the word cloud diagram (in the following figure The word cloud map is the shape of the cat), then use wc.WordCloud() to convert the word cloud map, and finally show the corresponding word cloud map by imshow(). For example, according to the old nine door. Txt document rendering word cloud effect as shown below:
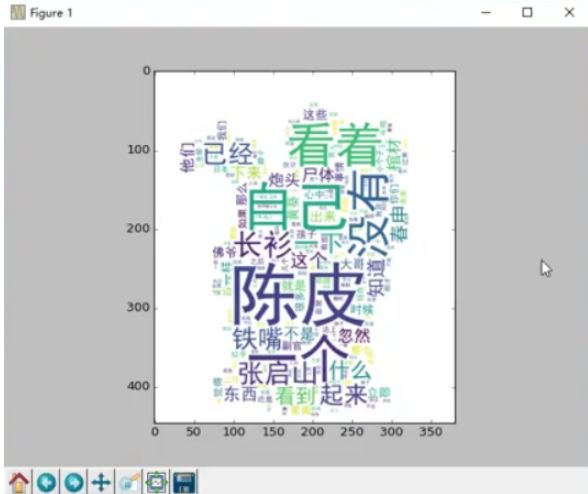
Third, the introduction of common classification algorithms
There are many common classification algorithms, as shown in the following figure:

Among them, KNN algorithm and Bayesian algorithm are both more important algorithms, in addition to other algorithms, such as decision tree algorithm, logistic regression algorithm and SVM algorithm. Adaboost algorithm is mainly used to transform weak classification algorithms into strong classification algorithms.
Fourth, the classification of iris flowers case actual combat
If there are some Iris data, these data include some of the characteristics of the iris, such as the length of the petals, the width of the petals, the length of the calyx, and the width of the calyx. With these historical data, these data can be used to train the classification model. After a model has been trained, when a new type of iris is not known, the trained model can be used to determine the type of iris. . This case has different implementations, but which classification algorithm will be used to achieve better?
1. KNN algorithm
KNN algorithm introduction:
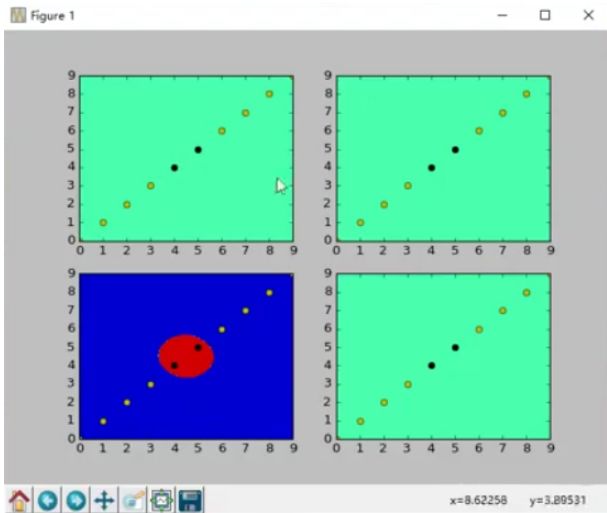
First of all, consider such a problem. In the above Taobao products, there are three types of products, namely, snacks, brand bags and electric appliances. They have two characteristics: price and comment. Sorting by price, branded bags are the most expensive, followed by appliances, and snacks are the cheapest; according to the number of reviews, the number of snack reviews is the highest, followed by electrical appliances, and brand name bags. Then use price as the x-axis and comment as the y-axis to establish the Cartesian coordinate system and plot the distribution of these three types of commodities in the coordinate system, as shown in the following figure:
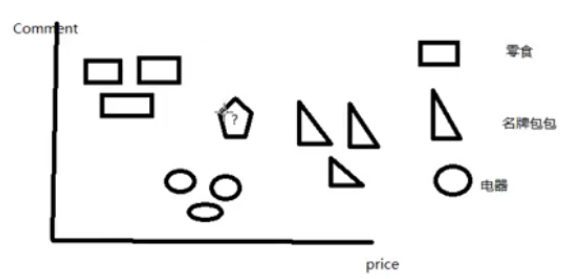
Obviously, it can be found that these three types of commodities are all concentrated in different regions. If you now have a new product that is known for its characteristics, use? Indicates this new product. According to its characteristics, the position of the product in the coordinate system mapping is as shown in the figure. Which of the three types of commodities is most likely to be the product?
This type of problem can be solved using the KNN algorithm. The idea of ​​this algorithm is to calculate the sum of the Euclidean distances of unknown goods to other individual goods, and then sort them. The smaller the sum of distances, the unknown goods and this The more similar the products are. For example, after the calculation, it is concluded that the sum of the Euclidean distances between the unknown commodity and the electronic commodity is the smallest, and the commodity can be considered as belonging to the electrical appliance category.
Method to realize:
The specific implementation of the above process is as follows:
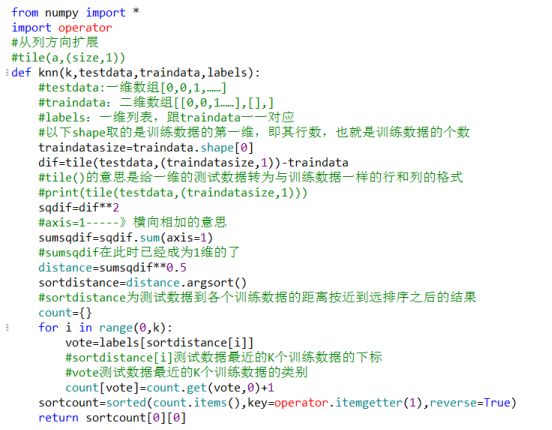
Of course, you can also directly tune the package, which is more concise and convenient, the disadvantage is that the people who use it can not understand its principle:

Use KNN algorithm to solve the problem of iris flower classification:
First load the iris data. There are two specific loading schemes. One is to read directly from the iris dataset. After the path is set, read through the read_csv() method to separate the characteristics and results of the dataset. The specific operations are as follows:

There is also a load method that uses sklearn to achieve loading. Sklearn's datasets have datasets with irises. The data can be loaded by using the datasets' load_iris() method. After that, the features and categories are also acquired. Then the training data and test data are separated (general cross-validation). Specifically, use the train_test_split() method to separate. The third parameter of this method represents the test proportion. The fourth parameter is a random seed. The specific operation is as follows:

After the loading is complete, the KNN algorithm mentioned above can be called to classify.
Bayesian algorithm
Bayesian algorithm introduction:
First, the naive Bayes formula is introduced: P(B|A)=P(A|B)P(B)/P(A). If there are some course data, as shown in the following table, prices and hours are characteristics of the course. Sales are the result of the course. If there is a new class, the price is high and there are many hours, and the new data is predicted based on the existing data. Class sales.
| Price (A) | Hours (B) | Sales volume (C) |
| low | many | high |
| high | in | high |
| low | less | high |
| low | in | low |
| in | in | in |
| high | many | high |
| low | less | in |
Obviously this issue belongs to the classification problem. The table is first processed and the feature one and the feature two are converted into numbers, ie 0 represents low, 1 represents medium, and 2 represents high. After digitization, [[t1,t2],[t1,t2],[t1,t2]]------[[0,2],[2,1],[0,0]], Then transpose this two-dimensional list (for subsequent statistics), and get [[t1,t1,t1],[t2,t2,t2]]-------[[0,2,0],[ 2,1,0]]. Where [0,2,0] represents the price of each course, [2,1,0] represents the number of hours of each course.
The original question can be equivalent to asking for the probability that the new course sales will be high, medium and low in the case of high prices and many hours. That is, P(C|AB)=P(AB|C)P(C)/P(AB)=P(A|C)P(B|C)P(C)/P(AB)=â€P(A) |C)P(B|C)P(C), where C has three conditions: c0=high, c1=medium, c2=low. In the end, we need to compare the sizes of P(c0|AB), P(c1|AB), and P(c2|AB).
P(c0|AB)=P(A|C0)P(B|C0)P(C0)=2/4*2/4*4/7=1/7
P(c1|AB)=P(A|C1)P(B|C1)P(C1)=0=0
P(c2|AB)=P(A|C2)P(B|C2)P(C2)=0=0
Obviously, P(c0|AB) is the largest, and the sales of this new class can be predicted to be high.
Method to realize:
Like the KNN algorithm, the Bayesian algorithm has two implementations, one is a detailed implementation:


The other is the integrated implementation:

3, the decision tree algorithm
The decision tree algorithm is based on the theory of information entropy. The algorithm's calculation flow is divided into the following steps:
Calculate total information entropy first
Calculate the information entropy of each feature
Calculate E and information gain, E = total information entropy - information gain, information gain = total information entropy - E
E If the smaller the information gain, the smaller the uncertainty
The decision tree refers to data for multiple features. For the first feature, whether to consider this feature (0 represents no consideration, 1 represents consideration) will form a binary tree, and then consider the second feature... until all All characteristics are considered and a decision tree is finally formed. The following figure is a decision tree:
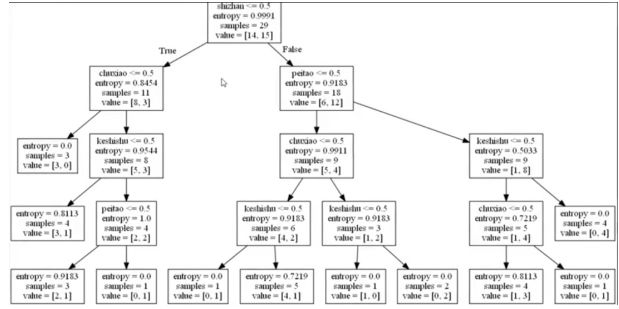
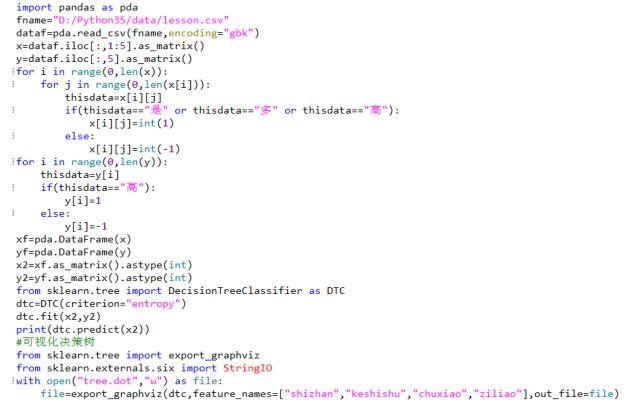
Decision tree algorithm implementation process is: first take out the data category, and then describe the transformation of the data (for example, "yes" is converted to 1, "no" is converted into 0), decision tree with the help of sklearn decision tree, use the fit () Method Data training is performed. Predict() can be used directly after training to obtain the prediction result. Finally, the decision tree is visualized using export_graphviz. The specific implementation process is shown in the figure below:
4, logistic regression algorithm
The logistic regression algorithm is implemented by means of the principle of linear regression. If there is a linear regression function: y=a1x1+a2x2+a3x3+...+anxn+b, where x1 to xn represent individual features, although this straight line can be used to fit it, but because the y range is too large, it leads to Robustness is bad. If you want to achieve classification, you need to narrow the range of y to a certain space, such as [0,1]. At this time, the reduction of the y range can be achieved by the substitution method:
Let y=ln(p/(1-p))
Then: e^y=e^(ln(p/(1-p)))
=> e^y=p/(1-p)
=>e^y*(1-p)=p => e^yp*e^y=p
=> e^y=p(1+e^y)
=> p=e^y/(1+e^y)
=> p belongs to [0,1]
In this way, y reduces the range, so that accurate classification can be achieved and logical regression can be realized.
The corresponding implementation process of the logistic regression algorithm is shown in the following figure:

5, SVM algorithm
SVM algorithm is a precise classification algorithm, but its interpretability is not strong. It can transform the problem of linear indivisibility of low-dimensional space into linear separability in high-order space. The use of SVM algorithm is very simple, direct import SVC, and then train the model and make predictions. The specific operation is as follows:

Although the implementation is very simple, the key to this algorithm is how to choose the kernel function. The kernel functions can be divided into the following categories. Each kernel function also applies to different situations:
Linear kernel function
Polynomial kernel function
Radial basis kernel function
Sigmoid kernel function
For data that is not particularly complex, linear or polynomial kernel functions can be used. For complex data, radial basis kernel functions are used. The image drawn with each kernel function is shown below:
5, Adaboost algorithm
If there is a single-level decision tree algorithm, it is a weak classification algorithm (algorithm with very low accuracy). If you want to strengthen this weak classifier, you can use the idea of ​​boost to achieve, such as the use of Adaboost algorithm, that is, multiple iterations, each time give different weights, while calculating the error rate and adjust the weight, and finally form A comprehensive result.
The Adaboost algorithm is generally not used alone, but is used in combination to enhance those weakly classified algorithms.
Fifth, classification algorithm selection ideas and techniques
First of all, it is to see whether it is a two-class or multi-classification problem. If it is a two-class problem, these algorithms can generally be used; if it is a multi-classification problem, KNN and Bayesian algorithms can be used. Second, whether or not high interpretability is required, if high interpretability is required, the SVM algorithm cannot be used. Look at the number of training samples and the number of training samples. If the number of training samples is too large, it is not appropriate to use the KNN algorithm. Finally, see if we need to carry out the weak-strong algorithm transformation, if you need to use Adaboost algorithm, otherwise do not use Adaboost algorithm. If you are not sure, you can select part of the data for validation and model evaluation (time and accuracy).
In summary, the advantages and disadvantages of each classification algorithm can be summarized as follows:
KNN: Multi-classification, inert calls, not suitable for training data
Bayes: Multi-category, large amount of calculation, no correlation between features
Decision tree algorithm: two categories, very interpretable
Logistic regression algorithm: two classifications, whether the features are related to each other does not matter
SVM algorithm: two categories, the effect is good, but the lack of interpretability
Adaboost algorithm: suitable for strengthening weak classification algorithms
Aluminum Laptop Cooling Stand,Aluminum Laptop Stand,Aluminum Laptop Stand 17 Inch,Aluminum Laptop Stand Adjustable,etc.
Shenzhen Chengrong Technology Co.ltd is a high-quality enterprise specializing in metal stamping and CNC production for 12 years. The company mainly aims at the R&D, production and sales of Notebook Laptop Stands and Mobile Phone Stands. From the mold design and processing to machining and product surface oxidation, spraying treatment etc ,integration can fully meet the various processing needs of customers. Have a complete and scientific quality management system, strength and product quality are recognized and trusted by the industry, to meet changing economic and social needs .

Aluminum Laptop Cooling Stand,Aluminum Laptop Stand,Aluminum Laptop Stand 17 Inch,Aluminum Laptop Stand Adjustable
Shenzhen ChengRong Technology Co.,Ltd. , https://www.laptopstandsuppliers.com