There is such a buzzword on the Internet: "Everything does not know how to ask." Since the emergence of various search engines, new nouns and new technologies are no longer mysterious to the public. However, when you search for keywords such as "Big Data" or "big data soluTIon", the vast amount of knowledge you search for is overwhelming, and it is still difficult for beginners to get started in a short time. The purpose of this article is to make it easy for beginners to understand "big data" in a foolish way.
Big data concept
"Big data", isn't it -- big data is called big data?
In fact, there is nothing wrong with this simple understanding. When defining clearly, it emphasizes the characteristics of the four Vs of big data: Volume, Variety, Value, Velocity. That is:
First, the data storage space is large (to PB and above);
Second, the data types are numerous;
Third, the value density is low;
Fourth, the processing speed is fast.
In the search for information, you will find that some nouns appear very frequently, and there will be some doubts in your heart. “How big is PB?†“Map-Reduce is 啥?†“Hadoop is 啥?†“The relationship between big data and cloud computing? What is the relationship with traditional database?†and so on.
With so much information, we still follow the basic definition of big data, and four Vs to sort out one by one.
Starting with the first V, Volume.
The amount of data is very large. What level can it reach? Let's learn about the knowledge of the order of magnitude.
1KB (Kilobyte kilobytes) = 2^10 B = 1024 B;
1MB (Megabyte megabytes) = 2^10 KB = 1024 KB = 2^20 B;
1GB (Gigabyte gigabytes) = 2^10 MB = 1024 MB = 2^30 B;
1TB (Trillionbyte terabyte) = 2^10 GB = 1024 GB = 2^40 B;
1PB (Petabyte beat) = 2^10 TB = 1024 TB = 2^50 B;
1EB (Exabyte) = 2^10 PB = 1024 PB = 2^60 B;
1ZB (Zettabyte Zebyte) = 2^10 EB = 1024 EB = 2^70 B;
1YB (YottaByte å°§ byte) = 2^10 ZB = 1024 ZB = 2^80 B;
1BB(Brontobyte ) = 2^10 YB = 1024 YB = 2^90 B;
1NB(NonaByte ) = 2^10 BB = 1024 BB = 2^100 B;
1DB(DoggaByte) = 2^10 NB = 1024 NB = 2^110 B;
......
"Wow! Potholes, all these nouns are related to big data? Do we need to master?" Don't be excited! In fact, KB, MB, GB we have often encountered in daily computer operations. Even terabytes of large hard drives have been used in home computers. What we call "big data", most of the products are still at the level of PB EB. What are the ZB, YB, BB, NB, DB, etc. behind, for the time being, when they are floating clouds~
The second V, Variety.
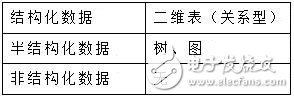
In this regard, Baidu Encyclopedia is said to be "web logs, videos, pictures, geographical location information, etc." From a professional point of view, we can say that in "big data", there can be structured data, but more is a large amount of unstructured and semi-structured data.
What does structured and unstructured data mean?
Structured data means that it can be stored in a database, and the two-dimensional table structure can be used to logically express the implemented data.
Unstructured data refers to data that is inconvenient to use a database two-dimensional logical table, including office documents, text, images, XML, HTML, various reports, images, and audio/video information in all formats.
Semi-structured data is data between fully structured data (such as relational databases, object-oriented databases) and completely unstructured data (such as sounds, image files, etc.). HTML documents are half. Structured data. It is generally self-describing, and the structure and content of the data are mixed together without a clear distinction.
The above description is actually a bit unclear. Looking at the list of data models, the difference is clearer:
The third V, Value.
The value density is low. Taking video as an example, in the continuous monitoring process, the data that may be useful is only one or two seconds.
The fourth V, Velocity.
Processing speed is fast. Such a huge amount of data needs to respond quickly in a short period of time. The technology used is of course different from traditional data mining techniques.
Interpretation
"After combing four Vs, is it still a cloud cover?"
Let's answer a few questions that beginners might think about!
For the four V of big data, is there any corresponding technology to deal with it?
At present, querying "Big Data", you will find that the word Hadoop appears frequently in various information given by Du Niang. Moreover, many vendors offer products with a label: "** products have been integrated into the Hadoop distributed computing platform, and Hadoop has been introduced into the product."
What is Hadoop?
Hadoop is a distributed system infrastructure developed by the Apache Foundation. It is a software framework that enables distributed processing of large amounts of data. Users can develop distributed programs without taking into account the underlying details of the distribution, making full use of the power of the cluster for high-speed computing and storage.
Hadoop includes the following subprojects:
1. Hadoop Common: In version 0.20 and earlier, including HDFS, MapReduce and other project public content, HDFS and MapReduce are separated into separate sub-projects from 0.21, and the rest is Hadoop Common.
2. HDFS: Hadoop Distributed File System - HDFS (Hadoop Distributed File System)
3. MapReduce: Parallel computing framework, using org.apache.hadoop.mapred old interface before 0.20, new version of org.apache.hadoop.mapreduce introduced in version 0.20
4. HBase: A distributed NoSQL column database similar to Google BigTable.
5. Hive: Data Warehouse Tool, contributed by Facebook.
6. Zookeeper: A distributed lock facility that provides Google Chubby-like features contributed by Facebook.
7. Avro: The new data serialization format and transport tool will gradually replace Hadoop's original IPC mechanism.
8. Pig: Big data analytics platform that provides users with multiple interfaces.
As a beginner, let's open some clouds and see what's in there. There are three main parts that we need to focus on: HDFS, MapReduce, HBase.
In fact, Apache Hadoop's HDFS is an open source implementation of the Google File System (GFS). MapReduce is an open source implementation of Google MapReduce. HBase is an open source implementation of Google BigTable.
Hadoop is a distributed computing platform that allows users to easily architect and use. It has the following main advantages: 1 high reliability 2 high scalability 3 high efficiency 4 high fault tolerance. Users can easily develop and run applications that process massive amounts of data on Hadoop. In fact, the big data products provided by many companies are also developed based on Hadoop.
Large data storage space
For the large data storage space, we need to use "distributed storage". A distributed storage system is to distribute data across multiple independent devices. The traditional network storage system uses a centralized storage server to store all data. The storage server becomes a bottleneck of system performance, and is also the focus of reliability and security, and cannot meet the needs of large-scale storage applications. The distributed network storage system adopts a scalable system structure, uses multiple storage servers to share the storage load, and uses the location server to locate the storage information, which not only improves the reliability, availability and access efficiency of the system, but also is easy to expand.
Hadoop, which we introduced earlier, is one of the most popular distributed storage platforms available today.
Brief description of the HDFS principle
HDFS (Hadoop Distributed File System) is a distributed file system. HDFS is highly fault-tolerant and designed to be deployed on low-cost hardware. It provides high throughput to access application data, suitable for applications with large data sets. HDFS relaxes the requirements of POSIX (requirements) so that streaming data can be accessed in the file system.
HDFS is a master-slave architecture. An HDFS cluster consists of a name node, which is a namespace for managing files and a master server that regulates client access to files. Of course, there are data nodes, one node, and it manages storage. HDFS exposes file namespaces and allows user data to be stored as files.
For external clients, HDFS is like a traditional hierarchical file system. You can create, delete, move or rename files, and more.
The internal mechanism is to split a file into one or more blocks, which are stored in a set of data nodes. The NameNode operates on a file or directory operation of a file namespace, such as open, close, rename, and so on. It also determines the mapping of blocks to data nodes. The DataNode is responsible for read and write requests from file system clients. The data node also performs block creation, deletion, and block copy indication from the name node. This is very different from the traditional RAID architecture. The size of the block (usually 64MB) and the number of blocks copied are determined by the client when the file is created. The NameNode can control all file operations.
All communications within HDFS are based on the standard TCP/IP protocol.
a wide variety of data types
Big data processing has the following requirements: the need for high concurrent read and write of the database, the need for efficient storage and access to massive data, the need for high scalability and high availability of the database. Traditional relational databases are at a loss in the face of such needs. At this point, a new concept was introduced -- NoSQL.
Hp Laptop Series,Laptop Parts,Laptop Palmrest,Hp Palmrest
S-yuan Electronic Technology Limited , https://www.laptoppalmrest.com