Editor's note: Multi-layer neural networks have achieved significant results on a variety of benchmark tasks, such as text, speech, and image processing. Nonetheless, these deep neural networks can lead to high-dimensional nonlinear parameter spaces, making searches difficult, and can also lead to overfitting and poor generalization. In the early days, the high capture probability caused by insufficient data, inability to recover the gradient loss, and poor local minimum made the neural network using backpropagation easy to fail.
In 2006, Hinton's deep learning proposed some innovative methods to reduce these over-fitting and over-parameterization problems, including ReLU and Dropout to reduce continuous gradient loss. In this article, two researchers from Rutgers University in the United States will pay attention to the problem of excessive parameterization of deep networks, although there are now a lot of available data for various classification tasks. This article has been submitted to NIPS 2018. The following is a rough compilation of the original text by Lunzhi. Please criticize and correct any errors.
Dropout is used to reduce over-parameterization, deep learning over-fitting, and to avoid accidental bad local minimums. Specifically, Dropout will add a Bernoulli random variable with probability p, delete hidden units and connections in the network every time it is updated, thereby creating a sparse network architecture. After learning, the deep learning network will reorganize by calculating the expected value of each weight. Most cases prove that Dropout of deep learning can reduce the errors of common benchmarks by more than 50%.
In this paper, we will introduce a general type of Dropout, which can operate at the weight level and insert gradient-related noise in each update, called the random delta rule (SDR). SDR is to implement a random variable on each weight and provide updated rules for each parameter in the random variable. Although SDR can work under any random variable, we will show that Dropout is very special with fixed parameters in binomial random variables. Finally, we tested DenseNet on a standard benchmark with Gaussian SDR, and the results proved that binomial Dropout has a very big advantage.
Random delta rule (SDR)
As we all know, neural transmission contains noise. If neurons separated from the cortex are subjected to periodic, identical stimuli, they will respond differently. Part of the motivation of SDR is based on the randomness of signal propagation between neurons in living systems. Obviously, the smooth nerve rate function is based on the average value of many stimulation experiments, which makes us think that the synapse between two neurons can be modeled with a distribution with fixed parameters.
Figure 1 shows the SDR algorithm we implemented with a Gaussian random variable and the average µwij and σwij. Each weight is sampled from Gaussian random variables. In fact, like Dropout, many networks are sampled during training updates. The difference between this and Dropout is that when the SDR is updated, the weights and hidden units are adjusted according to the wrong gradient.
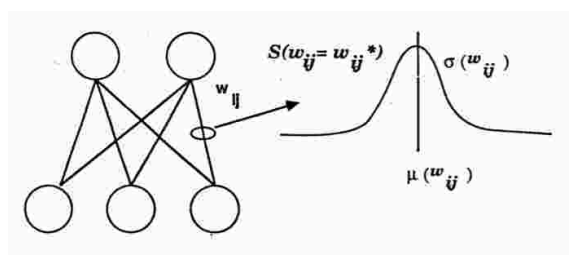
figure 1
Therefore, each weight gradient is a random variable based on the hidden unit. Based on this, the system can:
Given the same sample/reward, generate multiple response hypotheses
Keep historical predictions instead of only partial hidden unit weights like Dropout
It is possible to return to a bad local minimum and cause a greedy search, but at the same time it is getting farther and farther away from the better local minimum
The last advantage is that, as Hinton said, the insertion of local noise may lead to a faster and more stable convergence to a better local minimum.
There are three update rules for implementing SDR. The following are the update rules for the weight values ​​in the weight distribution:
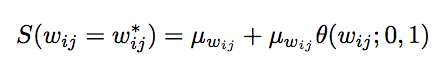
The first update rule is used to calculate the average of the weight distribution:
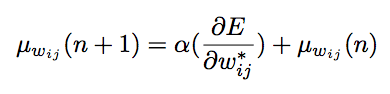
The second is for the standard deviation of the weight distribution:
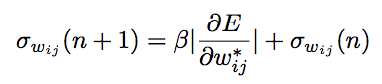
The third is to converge the standard deviation to 0, let the average weight value reach a fixed point, and gather all samples:
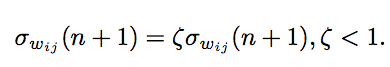
Next, we will talk about how Dropout became a special case of SDR. The most obvious method is to first treat random search as a special sampling distribution.
Think of Dropout as the binomial fixed parameter of SDR
As mentioned before, Dropout needs to delete the hidden units of each layer in the Bernoulli process. If we compare Dropout and SDR in the same network, we can find that the difference between the two lies in whether the random processing affects the weights or hidden units. In Figure 2 we describe the convergence of Dropout during hidden unit sampling. It can be seen that the obvious difference is that SDR is adaptively updating the random variable parameters, while Dropout uses fixed parameter entry and Binomial random variables for sampling. Another important difference is that the shared weight of SDR in the hidden layer is more "local" than Dropout.
figure 2
Then, does the increase in the parameters exhibited by SDR make the search more effective and more stable? In the next step we will carry out experiments.
Test and results
Here we use an improved DenseNet built on TensorFlow. The model uses DenseNet-40, DenseNet-100 and DenseNet-BC 100 networks, which have been trained by CIFAR-10 and CIFAR-100, and the initial DenseNet parameters are the same.
The final result showed that in the DenseNet test after replacing SDR with Dropout, the error rate dropped by more than 50%.
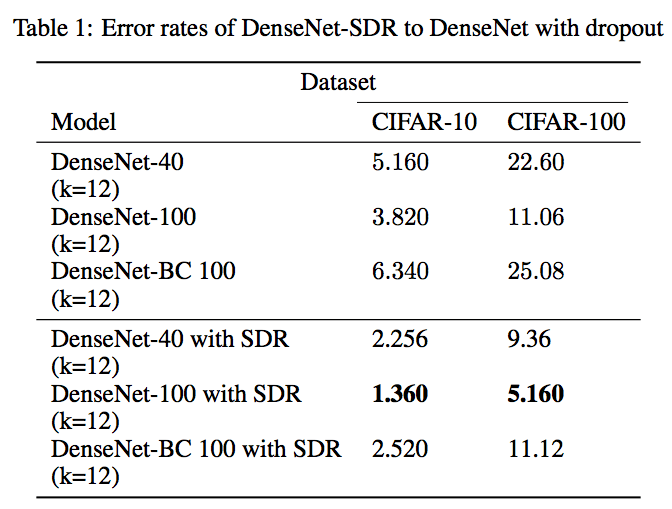
At the same time, when the error rate is 15, 10, and 5, the number of times required for training is also less than that of DenseNet alone:
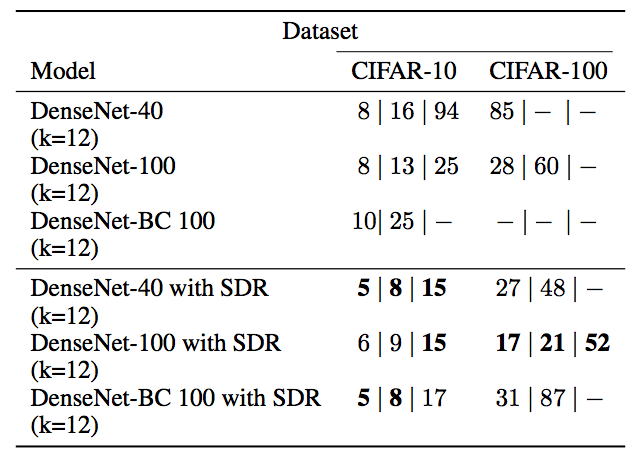
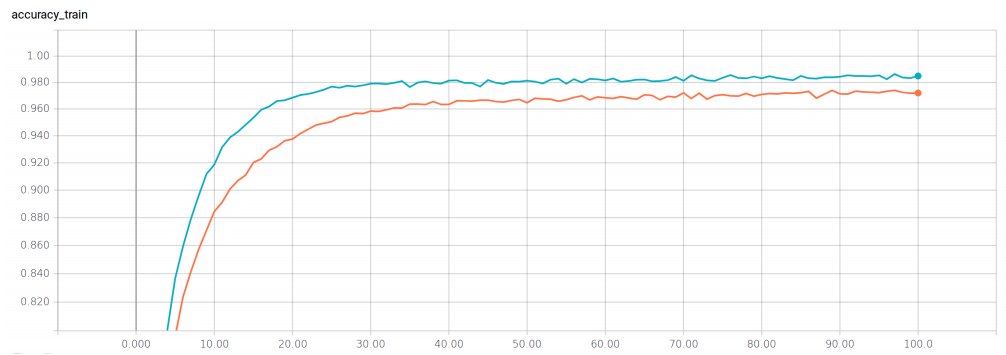
Training accuracy (DenseNet-100 orange, DenseNet-100 with SDR, blue)
Conclusion
This article shows how a basic deep learning algorithm (Dropout) implements random search and helps resolve overfitting. In the future, we will show how SDR surpasses Dropout's performance in deep learning classification.
Data scientist and fast.ai founder Jeremy Howard commented: "If the results of the paper are really so good, it definitely deserves attention."
But Google machine learning expert David Ha has a different opinion: "The results look suspicious (I think they got it wrong). The accuracy of CIFAR-10 can reach 98.64%, and can CIFAR-100 really reach 94.84%?"
The 7-inch tablet can be used as the golden size of a tablet computer. It is small and portable. It can be used at home and outdoors. You can browse the web, watch videos and play games. It is a household artifact. Although the size of the 7-inch tablet is inclined to the tablet, the function is more inclined to the mobile phone, so it can also be used as a substitute for the mobile phone. Compared with other sized tablets, the 7-inch tablet has obvious advantages in appearance and weight. Both the body size and the body weight have reached a very reasonable amount.
1.In appearance, the 7 inch tablet computer looks like a large-screen mobile phone, or more like a separate LCD screen.
2.In terms of hardware configuration, the 7 inch tablet computer has all the hardware devices of a traditional computer, and has its own unique operating system, compatible with a variety of applications, and has a complete set of computer functions.
3.The 7 inch tablet computer is a miniaturized computer. Compared with traditional desktop computers, tablet computers are mobile and flexible. Compared with Laptops, tablets are smaller and more portable
4.The 7 inch tablet is a digital notebook with digital ink function. In daily use, you can use the tablet computer like an ordinary notebook, take notes anytime and anywhere, and leave your own notes in electronic texts and documents.
7 Inches Tablet Pc,Quad Core Tablet 7 Inch,7 Inch Gaming Tablet,Supersonic Tablet 7 Inch
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisengroup.com