Deep learning is a field that requires high computing power. The choice of GPU will fundamentally determine your deep learning experience. If there is no GPU, it may take several months for you to complete the entire experiment. Even when you only want to see the effects of parameter adjustments and model modifications, it may take a day or more.
With good performance and stable GPU, people can quickly iterate on the architecture design and parameters of deep neural networks, compressing the months originally required to complete the experiment to a few days, or compressing a few days to a few hours, and compressing a few hours. To a few minutes. Therefore, it is very important to make the right choice when buying a GPU.
The following is a GPU selection suggestion given by Dr. Tim Dettmers of the University of Washington based on the experience of the competition. Readers in need can use it as a reference.

When one starts to dabble in deep learning, it is very important to have a high-speed GPU, because it can help people accumulate practical experience more efficiently, and experience is the key to mastering professional knowledge and can open the door to in-depth learning of new problems . Without this kind of quick feedback, the time cost for us to learn from our mistakes is too high, and at the same time, too long a time can be frustrating and frustrating.
Take my personal experience as an example. By configuring a reasonable GPU, I learned to use deep learning in a series of Kaggle competitions in a short time, and won the second place in the Chaly of Hashtags competition. At that time, I built a fairly large two-layer deep neural network, which contained linear neurons for rectification and a loss function for regularization.
With such a deep network, the 6GB GPU in my hand can't run. So after that I started with a GTX Titan GPU, which is also the main reason for the good results in the end.
Ultimate advice
The best GPU: RTX 2080 Ti
High performance-price ratio, but small and expensive: RTX 2080, GTX 1080
Cost-effective and cheap at the same time: GTX 1070, GTX 1070 Ti, GTX 1060
Data set used>250GB: RTX 2080 Ti, RTX 2080
Small budget: GTX 1060 (6GB)
Almost no budget: GTX 1050 Ti (4GB)/CPU (modeling) + AWS/TPU (training)
Participate in the Kaggle competition: GTX 1060 (6GB) (modeling) + AWS (final training) + fast ai library
Promising CV researcher: GTX 2080 Ti; upgrade to RTX Titan in 2019
Ordinary researcher: RTX 2080 Ti/GTX 10XX -> RTX Titan, pay attention to whether the memory is suitable
An ambitious deep learning rookie: start with GTX 1060 (6GB), GTX 1070, GTX 1070 Ti, and slowly advance
A rookie in deep learning that can play casually: GTX 1050 Ti (4 or 2GB)
Should I buy more GPUs?
At that time, I was very excited to see that GPUs could provide so many possibilities for deep learning, so I got into the "deep hole" of multiple GPUs: I assembled a small IB 40Gbit/s GPU array, hoping it could produce Give better results.
But the reality is very cruel. I was quickly "faced". It is not only very difficult to train neural networks on multiple GPUs in parallel, but also some commonly used acceleration techniques have little effect. It is true that a small neural network can greatly reduce the training time through data parallelism, but since I am building a large neural network, its efficiency has not changed much.
In the face of failure, I deeply researched parallelization in deep learning and published a paper on ICLR in 2016: 8-Bit Approximations for Parallelism in Deep Learning. In the paper, I proposed an 8-bit approximation algorithm, which can achieve a speedup of more than 50 times on a system containing 96 GPUs. At the same time, I also found that CNN and RNN are very easy to parallelize, especially when only one computer or 4 GPUs are used.
Therefore, although modern GPUs are not highly optimized for parallel training, we can still speed up "fancy".

The internal structure of the host: 3 GPUs and an IB card. Is this suitable for deep learning?
N card? A card? Intel? Google? Amazon?
NVIDIA: the leader
At a very early time, NVIDIA has provided a standard library, which makes it very easy to build a deep learning library in CUDA. In addition, AMD's OpenCL did not realize the prospect of the standard library at that time. NVIDIA combined this early advantage and strong community support to allow the rapid expansion of the CUDA community. So far, if you are a NVIDIA user, you can easily find deep learning tutorials and resources in various places, and most libraries also provide the best support for CUDA.
Therefore, if you want to start with NVIDIA's GPU, a strong community, rich resources and complete library support are definitely the most important factors.
On the other hand, considering that NVIDIA quietly revised the GeForce series graphics card driver end user license agreement at the end of last year, data centers are only allowed to use Tesla series GPUs, not GTX or RTX cards. Although they have not yet defined what a "data center" is, considering the legal risks involved, many institutions and universities are now starting to buy more expensive but inefficient Tesla GPUs-even if the price may differ by 10 times, Tesla cards There is no real advantage over GTX and RTX cards.
This means that as an individual buyer, when you accept the convenience and advantages of the N card, you must also be prepared to accept the "unequal" clause, because NVIDIA has a monopoly in this area.
AMD: powerful but lack of support
At the 2015 International Supercomputing Conference, AMD launched HIP, which can convert code developed for CUDA into code that can be run on AMD graphics cards. This means that if we have all the GPU code in HIP, this will be an important milestone. But three years later, we still haven't been able to witness the rise of A card in the field of deep learning, because it is too difficult to practice, especially when porting TensorFlow and PyTorch code bases.
To be precise, TensorFlow supports AMD graphics cards. All conventional networks can run on AMD GPUs, but if you want to build a new network, it will have a lot of bugs that will make you unhappy. In addition, the ROCm community is not very large, and there is no way to directly solve this problem. Coupled with the lack of financial support for deep learning development, AMD is nowhere close to NVIDIA.
However, if we compare the two next-generation products, we can find that AMD’s graphics cards show strong performance. In the future, Vega 20 may have computing power similar to Tensor-Core computing units.
In general, for ordinary users who just want the model to run smoothly on the GPU, I still can't find a reason to recommend AMD, and the N card is the most suitable. But if you are a GPU developer or someone who wants to contribute to GPU computing, you can support AMD and combat NVIDIA’s monopoly, because it will benefit everyone in the long run.
Intel: Try hard
After using Intel's Phi, I almost "black all my life". I don't think they are real competitors of NVIDIA or AMD cards, so here we are going to make a long story short. If you decide to start with Xeon Phi, here are the problems you may encounter: poor support, slower calculation code segment than C++PU, very difficult to write optimized code, C++11 is not fully supported, and some compilers do not support some Important GPU design patterns, poor compatibility with other libraries (NumPy and SciPy), etc.
I am really looking forward to Intel's Nervana Neural Network Processor (NNP), but since it was proposed, it has fallen into endless bouncing votes. According to recent reports, NNP will ship in the third/fourth quarter of 2019, but referring to their Xeon Phi, if we want to buy a mature technology NNP, it is estimated that we will have to wait until 2020 at least.
Google: Cheap services on demand?
Up to now, Google TPU has developed into a very mature cloud product with high cost performance. To understand TPU, we can simply think of it as multiple GPUs packaged together. If you have ever compared the performance gap between Tensor-Core-enabled V100 and TPUv2 on ResNet50, as shown in the figure below, you can find that the accuracy of the two is similar, but the TPU is cheaper.
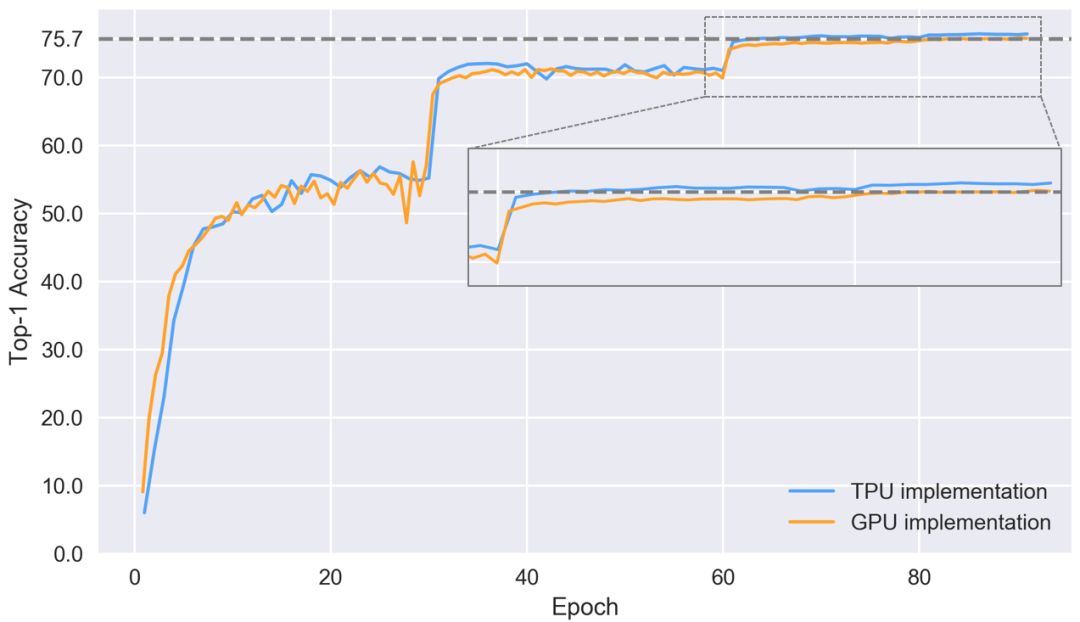
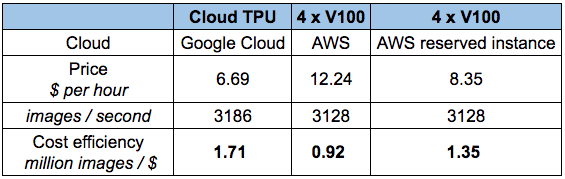
So if you have a tight hand and expect high performance, should you choose TPU? Yes, it is not. If you do thesis research or use it frequently, TPU is indeed an economical choice. However, if you have taken the fast ai class and used the fast ai library, you will find that you can achieve faster convergence at a lower price-at least for CNN target recognition.
In addition, although TPU is more cost-effective than other similar products, it also has many problems: (1) TPU cannot be used in fast ai library, namely PyTorch; (2) TPU algorithm mainly relies on Google's internal team; (3) Without a unified high-level library, it is impossible to provide a good standard for TensorFlow.
The above three points are the pain points of TPU, because it requires separate software to keep up with the update iteration of the deep learning algorithm. I believe that the Google team has completed a series of tasks, but their support for certain tasks is still unknown. Therefore, the current TPU is more suitable for computer vision tasks and as a supplement to other computing resources. I don't recommend developers to use it as their main deep learning resource.
Amazon: reliable but expensive
AWS's GPU is very rich, and the price is a bit high. If additional calculations are suddenly required, AWS GPU may be a very useful solution, for example, the deadline for the paper is approaching.
For economic reasons, if you want to buy Amazon services, you'd better run only part of the network and know exactly which parameters are closest to the best choice. Otherwise, these extra expenses due to your own mistakes may make your wallet bottom out. So, even if Amazon's cloud GPU is very fast, let's buy a dedicated physical graphics card by ourselves. The GTX 1070 is very expensive, but it can be used for at least one or two years.
What determines the speed of the GPU?
What makes this GPU faster than that GPU? Faced with this problem, the first thing you may think of is to look at the graphics card characteristics related to deep learning: is it the core of CUDA? What is the main frequency? How big is the RAM?
Although "seeing memory bandwidth" is a "panacea" term, I don't recommend it, because with the development of GPU hardware and software for many years, bandwidth is no longer the only synonym for performance. Especially with the introduction of Tensor Cores in consumer GPUs, this problem is even more complicated.
Now, if you want to judge the performance of the graphics card, its indicator should be bandwidth, FLOPS and Tensor Cores three in one. To understand this, we can look at where the two most important tensor operations, matrix product and convolution, are accelerated.
When it comes to matrix product, one of the simplest and most effective concepts is that it is limited by bandwidth. If you want to use LSTM and other RNNs that require a lot of matrix product operations, memory bandwidth is the most important feature of GPU. Similarly, convolution is constrained by computational speed, so for ResNets and other CNNs, TFLOP on the GPU is the best indicator of performance.
The emergence of Tensor Cores slightly changed the above balance. They are very simple dedicated computing units that can accelerate calculations-but not memory bandwidth-so for CNN, if there is Tensor Core in the GPU, the biggest improvement they bring is a speed increase of about 30% to 100%.
Although Tensor Cores can only increase the calculation speed, they can also use 16bit numbers for calculations. This is also a huge advantage for matrix multiplication, because in a matrix with the same memory bandwidth, the amount of information transmission for a 16-bit number is twice that of a 32-bit number. The reduction in the size of the digital memory is particularly important for storing more numbers in the L1 cache. When this is achieved, the larger the matrix and the higher the computational efficiency. So if Tensor Cores are used, its speed-up effect on LSTM is about 20% to 60%.
Please note that this acceleration does not come from Tensor Cores themselves, but from their ability to perform 16bit calculations. AMD GPUs also support 16bit number calculations, which means they are actually as fast as NVIDIA graphics cards with Tensor Cores when performing product operations.
A big problem with Tensor Cores is that they require 16-bit floating point input data, which may introduce some software support issues, because the network usually uses 32-bit. If there is no 16-bit input, Tensor Cores will be useless. However, I think these problems will be resolved soon, because Tensor Cores are too powerful. Now they have appeared in consumer GPUs. In the future, more and more people will use it. Please note that with the introduction of 16bit numbers into deep learning, GPU memory has actually doubled, because now we can store twice as many parameters in the same size of memory as before.
In general, the best rule of thumb is: if you use RNN, look at bandwidth; if you use convolution, look at FLOPS; if you have money, go to Tensor Cores (unless you have to buy Tesla).
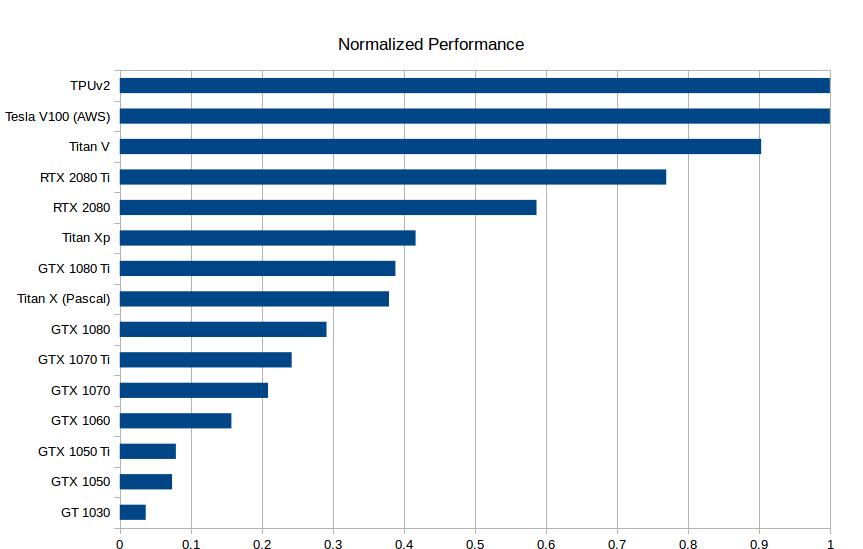
Standardized raw performance data of GPU and TPU, the higher the better
Cost-benefit analysis
The cost-effectiveness of the GPU may be the most important criterion for choosing a GPU. I did a new cost-effective analysis around bandwidth, TFLOP and Tensor Cores. First, the selling price of graphics cards comes from Amazon and eBay, and the weight of the two platforms is 50:50; second, I checked the performance indicators of Tensor Cores graphics cards on LSTM and CNN, and normalized these indicators. Perform weighting to get the average performance score; in the end, I calculated the following performance/cost ratio:
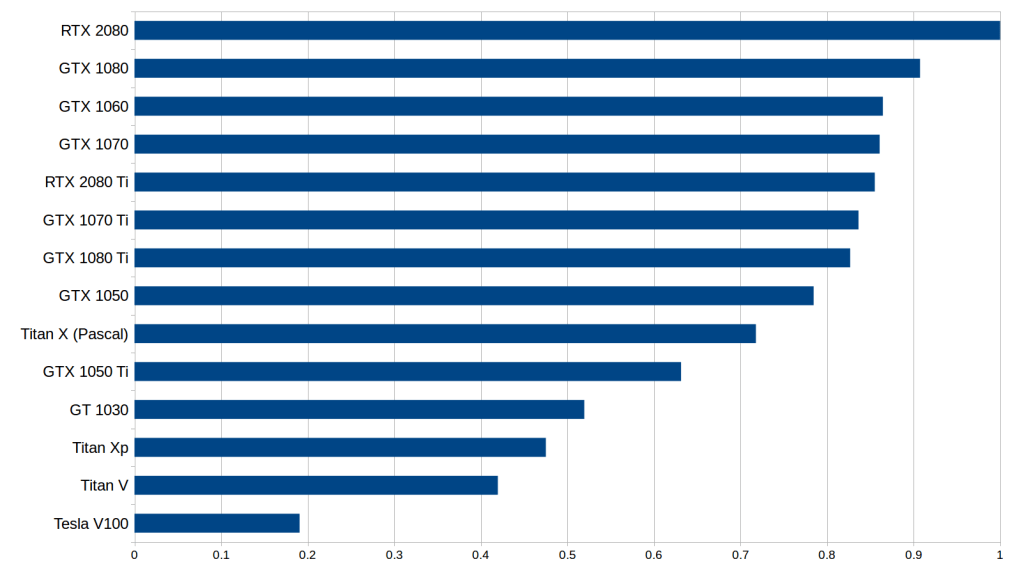
Around bandwidth, TFLOP and Tensor Cores cost performance, the higher the better
According to preliminary data, we can find that RTX 2080 is more affordable than RTX 2080 Ti. Although the latter has increased by 40% in Tensor Cores and bandwidth, and 50% in price, this does not mean that it can increase deep learning performance by 40%. For LSTM and other RNNs, the performance improvement brought by the GTX 10 series and RTX 20 series mainly comes from the support for 16-bit number calculations, not Tensor Cores; for CNN, although Tensor Cores have a significant increase in the calculation speed, it has a significant impact on the volume. Other parts of the product system structure also do not have auxiliary functions.
Therefore, compared to the GTX 10 series, the RTX 2080 has achieved a huge improvement in performance; compared to the RTX 2080 Ti, it has an advantage in price. Therefore, RTX 2080 is understandably the most cost-effective.
In addition, the data in the figure should not be superstitious. There are also some problems with this analysis:
If you buy a more cost-effective but slow graphics card, then your computer may not be able to install more graphics cards, which is a waste of resources. So in order to offset this deviation, the picture above will be biased towards more expensive GPUs.
This figure assumes that we are using a graphics card with Tensor Cores and 16bit calculations, which means that for RTX cards that support 32bit calculations, their cost performance will be statistically low.
Taking into account the existence of "miners", after the RTX 20 series is on sale, the prices of GTX 1080 and GTX 1070 may drop rapidly, which will affect the cost-effective ranking.
Because the product has not yet been released, the figures of RTX 2080 and RTX 2080 Ti in the table are not completely believed.
In summary, it is not easy to choose the best GPU from the perspective of cost performance. So if you want to choose a moderate GPU based on your own conditions, the following suggestions are reasonable.
General advice on GPU selection
At present, I would recommend two main options: (1) Buy the RTX series and use it for two years; (2) After the new product is released, buy the reduced price GTX 1080/1070/1060 or GTX 1080Ti / GTX 1070Ti.
For a long time, we have been waiting for GPU upgrades, so for many people, the first method is the most immediate and you can get the best performance now. Although the RTX 2080 is more cost-effective, the RTX 2080 Ti has more memory, which is a big temptation for CV researchers. So if you are looking for one step, it is a wise choice to buy these two graphics cards. As for which one to choose, in addition to the budget, the main difference between them is whether or not you need additional memory for the RTX 2080 Ti.
If you want to use 16bit calculations, choose Ti, because the memory will double; if there is no need for this, 2080 is sufficient.
As for the second method, it is a good choice for those who want to pursue a bigger upgrade and want to buy RTX Titan, because the price of GTX 10 series graphics cards may be reduced. Please note that GTX 1060 sometimes lacks certain models, so when you find a cheap GTX 1060, you must first consider whether its speed and memory really meet your needs. Otherwise, the cheap GTX 1070, GTX 1070 Ti, GTX 1080 and GTX 1080 Ti are also excellent choices.
For start-up companies, Kaggle contest participants, and novices who want to learn deep learning, my recommendation is the cheap GTX 10 series graphics cards, of which GTX 1060 is a very economical entry solution.
If you are a novice who wants to make a difference in deep learning, it is not bad to buy a few GTX 1060s and assemble them into an array at once. Once the technology is proficient, you can upgrade your graphics card to RTX Titan in 2019.
If you are short of money, I would recommend the GTX 1050 Ti with 4GB of RAM. Of course, if you can afford it, try to use the 1060. Please note that the advantage of GTX 1050 Ti is that it does not require additional PCIe to be connected to the PSU, so you can plug it directly into an existing computer to save additional money.
If you are short of money and value memory, eBay’s GTX Titan X is also worth buying.
I personally would buy an RTX 2080 Ti, because my GTX Titan X should have been upgraded long ago, and considering that the memory required for research is relatively large, and I plan to develop a Tensor Core algorithm by myself, this is the only choice.
summary
Seeing this, I believe that now you should know which GPU is more suitable for you. In general, I have two suggestions: get the RTX 20 series in one step, or buy a cheap GTX 10 series GPU. For details, refer to the "ultimate suggestions" at the beginning of the article. Performance and memory, as long as you really understand what you want, you can pick the most suitable graphics card for yourself.
Elevator Inverter,Frequency Inverter For Lift,Frequency Inverter For Elevator,Ac Drive For Elevator
Zhejiang Kaimin Electric Co., Ltd. , https://www.ckmineinverter.com