Introduction
Donkey Car is an open source DIY self-driving platform for model cars. It uses a Raspberry Pi microcontroller with a camera to allow model cars to drive automatically on the track. Donkey Car will learn your driving method and understand it after training. Autopilot. For those who have no background knowledge, the platform can provide the necessary details you need. It includes both hardware and software. After reading this tutorial, you can also assemble your own self-driving car without hardware background knowledge.
Now, the most common way to train a car for autonomous driving is behavior cloning and route following. At a high level, behavioral cloning uses convolutional neural networks to learn the mapping between the images taken by the camera in front of the car, and controls the direction and throttle through supervised learning. The route following is to use computer vision technology to track the route, and use a PID controller to make the car follow the route. I tried two methods and they are both useful!

Use behavioral cloning to train Donkey Car to avoid obstacles
Train Donkey Car with reinforcement learning
The important point is that the goal of Donkey Car is to build the fastest car in the race (to complete a lap at the fastest speed). I think reinforcement learning is a good way to train. Just design a reward that allows the car to reach the fastest speed and keep it on track all the time. Sounds simple, right? But in fact, many studies indicate that it is difficult to train reinforcement learning on physical targets. Reinforcement learning is mainly trained through trial and error. It is placed on the car. We can only bless the car not to crash in the repeated experiments. In addition, the length of training is also an issue. Generally, reinforcement learning agents have to train for hundreds of rounds to master some rules. Therefore, reinforcement learning is rarely used in real objects.
Simulated reality
Recently, some scientists have studied the simulation of reality, that is, first use reinforcement learning to train the car on a virtual simulator, and then transfer it to the real world. For example, recently OpenAI has trained a flexible robotic arm that can perform a variety of actions, and the entire process is trained in a virtual environment. In addition, Google Brain has also trained a quadruped robot that can learn flexible movements with technology that simulates reality. Learn the control strategy in the virtual machine, and then deploy it to the real robot. In this way, if you want to use reinforcement learning to train Donkey Car, a feasible solution is to use simulator training first, and then apply the learned strategy to the real car.

OpenAI trained manipulator
Donkey Car simulator
The first step is to build a high-fidelity simulator for Donkey Car. Fortunately, a fan in the Donkey Car community created an emulator in Unity. But its design purpose is mainly for behavioral learning (that is, the pictures in the camera are saved in the corresponding control angle and throttle size files for supervised learning), but it has nothing to do with reinforcement learning. What I hope is that there is an interactive interface similar to OpenAI Gym, where you can use reset() to reset the environment and operate it. So, I decided to modify it on the basis of the existing Unity simulator to make it more suitable for reinforcement learning.
4.1 Create a way to communicate with Python and Unity
Because we want to write reinforcement learning code in Python, we must first find a way to use Python in the Unity environment. As a result, I found out that the existing simulator also uses Python code to communicate, but it uses the Websocket protocol. Unlike HTTP, Weosocket supports two-way communication between the server and the client. In our case, our Python "server" can directly push information (direction and throttle) to Unity, and our Unity "client" can also push information (status and feedback) to the server in reverse.
In addition to Websocket, I also consider using gRPC, a high-performance server-client communication framework, open sourced by Google in August 2016. Unity uses it as a protocol for machine learning agent interface communication. But its setting is a bit cumbersome and not efficient, so I still choose Websocket.
4.2 Create a customized environment for Donkey Car
The next step is to create an interactive interface similar to OpenAI gym for training reinforcement learning algorithms. Those who have trained reinforcement learning algorithms before may be familiar with the use of various APIs. Common ones are reset( ), step( ), isgameover( ), etc. We can expand the types of OpenAI gym, and then use the above method to create our own gym environment.
The final result can be comparable to OpenAI gym. We use similar commands to interact with the Donkey environment:
env = gym.make("donkey-v0")
state = env.reset()
action = get_action()
state, action, rewards, next_state = env.step(action)
The environment also allows us to set frame_skipping and train the agent in headless mode (that is, without Unity GUI).
At the same time, Tawn Kramer also has 3 Unity scenes available: spawning roads, warehouses and Sparkfun AVC, all of which can be used for training. Before we start to run our own reinforcement learning algorithm, we either build the Unity environment of Donkey Car ourselves, or download the pre-built environment executable program. Specific environment settings and training instructions can be found in my GitHub: github.com/flyyufelix/donkey_rl
4.3 Train Donkey Car with DDQN
Prepared for an environment friendly to reinforcement learning, we can now build our own reinforcement learning algorithm! I used the Double Deep Q learning algorithm written in Keras, which is a classic reinforcement learning algorithm developed by DeepMind, which is easy to test and simple to write. I have tested it in cartpole and VizDoom in OpenAI gym, so if there is any problem, it should be the problem of Unity environment, and the algorithm is no problem. For articles about DQN, you can refer to my previous blog post. flyyufelix.github.io/2017/10/12/dqn-vs-pg.html
4.3.1 State space
We use the pixel photos taken by the camera installed in front of the Donkey Car to perform the following conversions:
Change the size from (120, 160) to (80, 80)
To grayscale image
Frame stacking: Go to the 4 frames stacked in the previous steps
The final state dimension should be (1, 80, 80, 4).
4.3.2 Action space
The Donkey Car in the real and virtual worlds both use continuous directional control and throttle values ​​as inputs. For the sake of introduction, we set the throttle value to a constant value (for example, 0.7) and only change the control direction. The value of the control direction ranges from -1 to 1. However, DQN can only handle separate actions, so I divide the value of the direction into 15 categories.
4.3.3 Q network framework
Our Q network is a 3-layer convolutional neural network, which takes the stacked frame state as input and outputs 15 values ​​representing the classification of directional values.
4.3.4 Rewards
The reward is a function of how far the car deviates from the center line, and it is provided by the Unity environment. The reward function is expressed by the following formula:
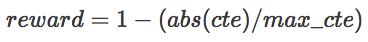
Where maxcte is a normalization constant, so the reward range is between 0 and 1. If abs(cte) is greater than maxcte, the loop terminates.
4.3.5 Other important variables
Frame skipping is set to 2 to stabilize training. The value of Memory replay buffer is 10000. The Target Q network will be updated in the final training. The Batch size during CNN training is 64. Greedy functions are used for exploration. The initial value of Epsilon is 1, and it will gradually become 0.02 after 10,000 training sessions.
4.3.6 Results
After the above settings, I trained DDQN almost 100 times on a single CPU and a GTX 1080 GPU. The entire training took 2 to 3 hours. As you can see from the video above, the car is running very well!
Remove background noise
We want our reinforcement learning agent to make decision output (that is, direction control) only based on the location and direction of the route, and not be affected by other factors in the environment. However, since our input is a full-pixel image, it may overfit the background pattern and fail to recognize the path of travel. This is especially important in reality, because there may be obstacles in the lane next to it (such as tables, chairs, pedestrians, etc.). If we want to transfer the learning strategy from the virtual world, we should let the agent ignore the noise in the background and focus only on the lane.
In order to solve this problem, I created a preprocessing channel that can separate the driving route from the original pixel image and input it into the CNN. The segmentation process is inspired by this blog post (https://medium.com/@ldesegur/a-lane-detection-approach-for-self-driving-vehicles-c5ae1679f7ee). The process is summarized as follows:
Detect and extract all borders with Canny Edge detector
Use Hough straight line transformation to determine all straight lines
Divide straight lines into positive sloped and negative sloped categories
Delete all straight lines that do not belong to the lane
The final converted image should have at most 2 straight lines, the details are as follows:

Then I re-adjusted the segmented image to (80, 80), stacked 4 consecutive frames together, and used them as the new input state. I trained the DDQN again with the new state, and the generated reinforcement learning agent can learn good strategies for driving!
However, I noticed that not only the training time will be longer, the learning strategy will also become unstable, and the car will often shake when turning. I think it might be because useful background information was lost during training. Otherwise, the agent should not overfit.
Next step
In this article, we introduced an environment comparable to OpenAI gym for training Donkey Car in the Unity simulator. It also uses DDQN to train it to automatically and successfully drive automatically. Next, I plan to let the car accelerate to the maximum through training, and transfer this strategy to reality.
Outdoor Led Screen,Outdoor Waterproof Led Screen,Waterproof Led Screen,Outdoor Led Display Screen
APIO ELECTRONIC CO.,LTD , https://www.apiodisplays.com